 Tabla de contenidos
Tabla de contenidos  SMTP: Referencias
SMTP: ReferenciasTabla de contenidos SMTP: Referencias
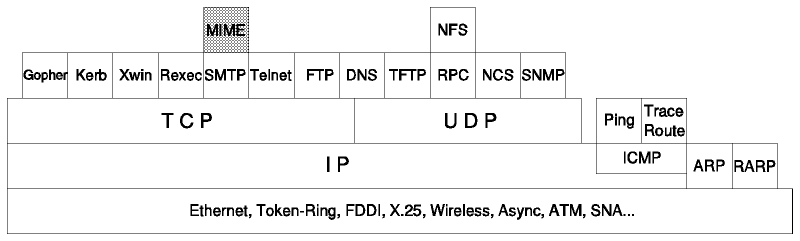
Figura: MIME("Multipurpose Internet Mail Extensions")
El MIME es un borrador. Su status es electivo.
El E-mail (como se describe en SMTP("Simple Mail Transfer Protocol")) es probablemente la aplicación TCP/IP más usada. Sin embargo, SMTP (es decir, un sistema de correo que sigue la norma STD 10/RFC 821) se limita a texto ASCII de 7 bits con una longitud de línea máxima de 100 caracteres lo que da lugar a diversas limitaciones.
Ninguna de ellas se puede considerar un estándar de facto. UUencode es quizás la más extendida debido a que los sistemas UNIX son los pioneros de Internet.
Obviamente, esto no es deseable ya que se trata de información presumiblemente importante aunque el sistema de correo no la pueda entender. Desecharla significa que será inaccesible al usuario. Convertirla a ASCII implica poner a cero el byte de orden superior, lo que supone la corrupción de los datos más haya de cualquier forma de recuperación. El problema es particularmente agudo en el caso de que emisor y receptor se hallen en redes X.400 pero el correo pase por una red RFC 822 intermedia("tunnelling") ya que los usuarios de X.400 esperan recibir correos X.400 sin perder información.
MIME es un estándar que incluye mecanismos para resolver estos problemas en una forma con un alto grado de compatibilidad con los estándares RFC 822. Debido a que los mensajes de correo suelen enviarse a través de pasarelas de correo, a un cliente SMTP no le es posible distinguir entre un servidor que gestiona el buzón del receptor y uno que actúa como pasarela a otra red. Como el correo que atraviesa una pasarela se puede dirigir a otras pasarela, que pueden usar distintos protocolos de mensajería, en el caso general al emisor no le es posible determinar el mínimo común denominador de las capacidades de cada una de las etapas que atraviesa el mensaje. Por este motivo, MIME asume el peor caso: transporte ASCII de 7 bits que puede no seguir estrictamente el RFC 821. No define ninguna extensión al RFC 821, sino que se limita sólo a las extensiones incluidas en el RFC 822. De esta forma, un mensaje MIME puede ser enrutado a través de cualquier número de redes capaces de transmitir mensajes RFC 821. Se describe en dos partes:
Aunque el RFC 1521 proporciona un mecanismo adecuado para describir dato de texto de mensajes X.400 en una forma no compatible con el RFC 822, no dice como se han de mapear las partes de los mensajes X.400 a las de los mensajes MIME. Esta conversión está definida en los RFCs 1494, 1495 y 1496 que actualizan los protocolos de conversión de RFC 822 a X.400.
El estándar MIME se diseñó con el siguiente orden general de prioridades:
Hay dos áreas en las que la compatibilidad con estándares previos no es completa.
La cuestión de compatibilidad más importante es que la forma estándar de un mensaje MIME sea legible con un lector de correo RFC 821. El caso es que, precisamente, la codificación estándar de los cuerpos de los mensajes MIME es exactamente RFC 822.
**** NOTA: ****
MIME no requiere que los objetos de correo estén codificados -- la decisión se deja al usuario y/o programa de correo. Para datos binarios, transmitidos a través de SMTP de 7 bits, la codificación es necesaria invariablemente, pero para datos que son texto en su mayoría, puede que no haga falta.El mecanismo preferido de codificación para datos "de texto en su mayoría" es tal que, como mínimo, es , es fiable para cualquier agente SMTP en un sistema ASCII, y como máximo, es fiable con todas las pasarelas y MTAs conocidos. La razón por la que MIME no requiere codificación total es que la codificación dificulta la legibilidad cuando MIME el correo se transmite a sistemas no MIME.
Para ver la lista actual de valores MIME, consultar STD 2 - Números asignados de Interne. El resto del capítulo describe los valores y tipos del RFC 1521.
Una consecuencia de este enfoque es que, citando al RFC 1521, "algunos de los mecanismo[usados en MIME] pueden parecer extraños o incluso barrocos al principio. En particular, siempre se ha favorecido la compatibilidad sobre la elegancia."
Debido a que el RFC 822 define la sintaxis de las cabeceras(y deliberadamente permite la extensión del conjunto de cabeceras que describe) pero no la composición de los cuerpos, el estándar MIME es muy compatible con el RFC 822, particularmente con la parte del RFC 1521 que define la estructura de los cuerpos de los mensajes y un conjunto de cabeceras que constituyen una descripción de estos.
MIME se puede ver como un protocolo de alto nivel; como trabaja enteramente dentro de los límites de los STDs 10 y 11, no implica en absoluto a los protocolos de transporte(o inferiores) de la pila de protocolos.
Un mensaje MIME debe contener un campo de cabecera con el siguiente texto:
MIME-Version: 1.0
Como en el caso de las cabeceras RFC 822, los nombres de los campos de la cabecera MIME no son sensibles a mayúsculas y minúsculas, pero los valores de los campos pueden serlo, según su nombre y contexto. Los valores de los campos MIME señalados abajo no lo son, a menos que se diga lo contrario.
La sintaxis general para los campos de la cabecera MIME es la misma que en RFC 822, por lo que el siguiente campo:
MIME-Version: 1.0 (comentario)
es válido ya que las frases entre paréntesis se tratan como comentarios y se ignoran.
En MIME se definen cinco campos de cabecera.
Nota: el RFC 1521 incluye una definición del término "cuerpo" tal como se emplea arriba, además de los términos "parte del cuerpo", "entidad", y mensaje. Desafortunadamente las cuatro definiciones son "pescadillas que se muerden la cola" porque el mensaje MIME genérico puede contener recursivamente mensajes MIME hasta cierta profundidad. La forma más simple de cuerpo es el cuerpo del mensaje como lo define el RFC 822.
Los dos primeros campos se describen con detalle en las siguientes seccione.
El cuerpo del mensaje se describe con un campo Content-Type de la forma:
Content-Type: type/subtype ;parameter=value ;parameter=value
Los parámetros admisibles son dependientes de "type" y "subtype". Algunos pares "type/subtype", algunos los tienen opcionales, otros obligatorios, y otros ambos. El parámetro de "subtype" no se puede omitir, pero sí todo el campo, y en este caso el valor por defecto es text/plain.
Hay siete "content-types" estándares:
Se pueden añadir nuevos "subtypes" para describir otros formatos de texto(tales como formatos de procesadores de texto) que contengan información para que una aplicación mejore el aspecto del texto, siempre que el software en cuestión no tenga que interpretar el significado del texto.
Content-Type: multipart/mixed; boundary="1995021309105517"
Un ejemplo complejo se muestra en Figura - Ejemplo de un mensaje "multipart" complejo.
MIME-Version: 1.0
From: Steve Hayes <steve@hayessj.bedfont.uk.ibm.com>
To: Matthias Enders <enders@itso180.itso.ral.ibm.com>
Subject: Multipart message
Content-type: multipart/mixed; boundary="1995021309105517"
Esta sección se llama preámbulo. Va tras la cabecera pero después del primer separador. Los lectores de correo que entiendan mensajes "multipart" deben ignorarlo.
--1995021309105517
La primera parte. No hay cabecera, por lo que se trata de "text/plain" con el juego de caracteres
"charset=us-ascii"por defecto. El <CRLF> adyacente es parte de la secuencia <CRLF><CRLF>
que termina la cabecera nula. El último es parte del siguiente separador, por lo que esta parte consiste
en cinco líneas de texto con cuatro <CRLF>s.
--1995021309105517
Content-type: text/plain; charset=us-ascii
Comments: this header explicitly states the defaults
Sólo una línea, acabada en salto de línea
--1995021309105517
Content-Type: multipart/alternative; boundary=_
Comments: An encapsulated multipart message!
De nuevo, este preámbulo se ignora. El cuerpo "multipart" contiene una imagen estática y una imagen de vídeo
codificadas en Base64. Ver Codificación Base64
Una característica es que el carácter "_", permitido en separadores "multipart", no aparece nunca en la
codificación Base64, por lo que se puede usar un separador muy sencillo:
--_
Content-type: text/plain
Este mensaje contiene imágenes que no se pueden visualizar en la terminal.
--_
Content-type: image/jpeg
Content-transfer-encoding: base64
Comments: This photograph is to be shown if the user's system cannot display
MPEG videos. Only part of the data is shown in this book because
the reader is unlikely to be wearing MIME-compliant spectacles.
Qk1OAAAAAAAAAE4EAABAAAAAQAEAAPAAAAABAAgAAAAAAAAAAAAAAAAAAAAAAAABAAAAAQAAAAAA
AAAAAAAAAAAAAAAAAAAAAAB4VjQSAAAAAAAAgAAAkgAAAJKAAKoAAACqAIAAqpIAAMHBwQDJyckA
/9uqAKpJAAD/SQAAAG0AAFVtAACqbQAA/20AAAAkAABVkgAAqiQAAP+SAAAAtgAAVbYAAKq2AAD/
<base64 data continues for another 1365 lines>
--_
Content-type: video/mpeg
Content-transfer-encoding: base64
AAABswoAeBn//+CEAAABsgAAAOgAAAG4AAAAAAAAAQAAT/////wAAAGy//8AAAEBQ/ZlIwwBGWCX
+pqMiJQDjAKywS/1NRrtXcTCLgzVQymqqHAf0sL1sMgMq4SWLCwOTYRdgyAyrhNYsLhhF3DLjAGg
BdwDXBv3yMV8/4tzrp3zsAWIGAJg1IBKTeFFI2IsgutIdfuSaAGCTsBVnWdz8afdMMAMgKgMEkPE
<base64 data continues for another 1839 lines>
--_--
fin del mensaje "multipart" anidado. Este es el epílogo. Como el preámbulo, se ignora.
--1995021309105517--
Fin del mensaje.
Figura: Ejemplo de un mensaje "multipart" complejo
El mensaje original es siempre un mensaje que sigue las reglas RFC 822. La primera parte es sintácticamente equivalente a un mensaje "messagge/rfc822"(es decir, el propio cuerpo contiene cabeceras) y las partes siguientes a mensajes "text/plain". Al reconstruir el mensaje, los campos de cabecera RFC822 se toman del mensaje de alto nivel, con la excepción de aquellos campos que no se pueden copiar del mensaje interior al exterior cuando existe fragmentación(por ejemplo, el campo "Content-Type").
Nota: está permito de forma explícita fragmentar aún más un mensaje "messagge/partial". Esto permite que las pasarelas de correo fragmenten los mensajes libremente para asegurarse de que todas las partes son lo bastante pequeñas para ser transmitidas. Si este no fuera el caso, el agente de correo que realice la fragmentación tendría que conocer el mínimo tamaño máximo que los correos se encontrarían en su ruta hacia el destino.
Cuando el objeto externo ha sido recibido, el mensaje deseado se obtiene añadiendo el objeto a la cabecera del mensaje encapsulado dentro del cuerpo del mensaje "message/external-body". Esta cabecera encapsulada tiene que se interpretada(ha de tener un campo "Content-ID:'' , y normalmentte tendrá un campo "Content-Type:"). El cuerpo encapsulado no se usa(después de todo, el mensaje real está en algún otro lado) y por tanto se denomina "cuerpo fantasma". Hay una excepción a esto: si el "access type" es "mail-server" el cuerpo fantasma contiene los comandos del servidor de correo necesarios para extraer el cuerpo real del mensaje. Esto se debe a que las sintaxis del servidor de correo varían mucho y es mucho más sencillo usar el cuerpo fantasma, que de otra forma sería redundante, que codificar una sintaxis para codificar comandos arbitrarios del servidor de correo como parámetros del campo "Content-Type:".
Obviamente, hay muchos tipos de datos que no caen dentro de ninguno de los subtipos indicados arriba. Los programas de correo cooperativos, manteniendo las reglas del RFC 822, usan tipos y/o subtipos que comienzan por "X-" como valores privados. No se permiten otros valores que no hayan sido registrados previamente con IANA. Ver el RFC 1590 para más detalles. La intención es que se necesiten pocos o ningún tipo adicional, pero que se añadan muchos subtipo al conjunto.
Como ya se ha indicado, los agentes SMTP y las pasarelas de correo pueden ejercer fuertes restricciones sobre los contenidos de los mensajes que se pueden transmitir fiablemente. Los tipos MIME descritos arriba son una lista de un variado conjunto de distintos tipos de objetos que se pueden incluir en un correo y la mayoría de ellos no se hallan dentro de estas restricciones. Por lo tanto, es necesario codificar estos datos de forma que se puedan transmitir y decodificar a su recepción. RFC 1521 define dos formas fiables de codificación. La razón de que haya dos formas y no una es que no es posible, dado el pequeño conjunto de caracteres fiables, desarrollar una sola forma que codifique tanto texto con un impacto mínimo en la legibilidad y datos binarios de un modo lo bastante compacto como para ser práctico.
Estas dos codificaciones se usan sólo para los cuerpos, no para las cabeceras. La codificación de cabeceras se describe en Usando caracteres no-ASCII en las cabeceras de los mensajes. El campo "Content-Transfer-Encoding:" define la codificación usada. Aunque engorroso, este campo enfatiza el hecho de que la codificación es una característica del transporte y no una propiedad intrínseca del objeto enviado. A pesar de haber sólo dos formas de codificación, este campo puede tomar cinco valores(no sensibles a mayúsculas y minúsculas). Tres de ellos especifican que no se ha realizado ninguna codificación; la diferencia entre ellos reside en que cada uno implica distintas razones por las que no ha habido codificación. Es un punto sutil pero importante. SMTP no es el único agente de correo posible de MIME, a pesar de la popularidad de sistemas de correo SMTP en Internet. Por ello, MIME permite la transmisión de datos no fiables por los estándares SMTP(STD 10/RFC 821). Si un correo de esta clase alcanza una pasarela para pasar a un sistema más restrictivo, el mecanismo de codificación especificado permite a la pasarela decidir, para cada ítem de correo, si el cuerpo se debe codificar para transmitirlo fiablemente.
Las cinco "codificaciones" son:
Se describen en la siguiente sección.
Codificación 7bit significa que no se ha hecho ninguna codificación y que el cuerpo consiste en líneas de texto ASCII con longitud no mayor de 1000 caracteres. Por ello, es fiable para cualquier sistema de correo que siga estrictamente las normas STD 10/RFC 821(por defecto, ya que son las restricciones que se aplican a los mensajes pre-MIME STD 11/RFC 822).
Nota: esta codificación no garantiza la total fiabilidad de los contenidos por dos razones. Primero, porque las pasarelas a redes EBCDIC tienen un conjunto de caracteres fiables más pequeño, y segundo, porque hay muchas implementaciones que no siguen SMTP.
Codificación 8bit implica que las líneas son lo bastante cortas para el transporte SMTP, pero que puede haber caracteres no ASCII. Esta codificación sólo es posible en los agentes SMTP que soporten el SMTP Service Extension for 8bit-MIMEtransport("Extensión SMTP para transporte MIME de 8 bits"), descrito en el RFC 1652. En otro caso, las implementaciones de SMTP deberían poner el bit de orden superior a cero, de modo que la codificación 8bit no sería válida.
Indica que pueden aparecer caracteres no-ASCII y que las líneas pueden ser demasiado largas para el transporte SMTP(es decir, puede haber secuencias de 999 ó más caracteres sin una secuencia CRLF). En la actualidad no estándares para el transporte de datos binarios sin codificar en sistemas de correo de TCP/IP, por lo que el único caso en el que se puede usar codificación "binary" en un mensaje MIME en una red TCP/IP es en la cabecera de un parte externa de un cuerpo. Se podría usar en otros casos si MIME se empleara junto con otros mecanismos de transporte o con una extensión hipotética de SMTP.
Es la primera de las dos codificaciones propiamente dichas y su fin es mantener la máxima legibilidad de los ficheros de texto en su forma codificada.
Esta codificación utiliza el signo igual para señalar estos dos casos. Tiene cinco reglas que son:
Este esquema es un compromiso entre legibilidad, eficiencia y robustez. Como las reglas 1 y 2 utilizan la expresión "se pueden codificar", las implementaciones tienen bastante libertad a la hora de decidir a cuántos caracteres les aplican estas reglas. Si se aplican en el mínimo número de caracteres, la codificación funcionará con agentes SMTP ASCII fiables. Para pasarelas EBCDIC fiables, se añade el siguiente conjunto de caracteres ASCII:
! " # $ @ [ \ ] ^ ` { | } ~
a la lista de caracteres a los que les son aplicables las reglas. Para una robustez total, es mejor aplicar las reglas a todos los caracteres, excepto al conjunto de 73 caracteres que no varía al atravesar la pasarela, es decir, las letras(A-Z,a-z), los dígitos(0-9) y los siguientes 11 caracteres:
' ( ) + , - . / : = ?
Nota: Esta lista de invariantes ni siquiera incluye el carácter SPACE. Con fines prácticos, al codificar ficheros de texto sólo se debería marcar con las reglas un SPACE al final de la línea. De otra forma, la legibilidad se ve seriamente afectada.
Esta codificación se destina a datos que no consisten principalmente en texto. Trata el flujo de entrada como un flujo de bits, reagrupando los bits en bytes más cortos, que luego rellena hasta 8 bits para traducirlos a caracteres fiables. Como se indicó en la sección previa, sólo hay 73 caracteres fiables, por lo que la longitud máxima utilizable de cada byte es de 6 bits, que se pueden representar con sólo 64 caracteres(de hay el nombre "Base64"). Como tanto la entrada como la salida son flujos de bytes, la codificación se debe hacer en grupos de 24 bits(3 de entrada y cuatro de salida). El proceso se puede ver de la siguiente forma:
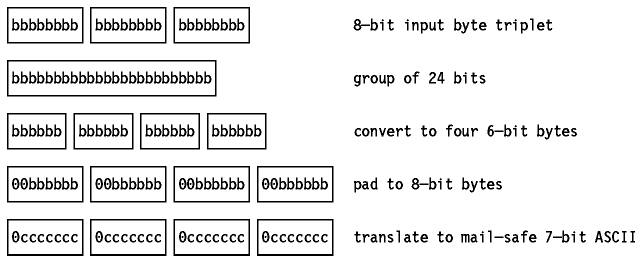
Figura: Codificación "Base64" - Conversión de 3 bytes de entrada a 4 bytes de salida en el esquema de codificación "Base64".
La tabla de traducción usada se llama el alfabeto "Base64".
Figura: El alfabeto "Base64"
Se necesita un carácter adicional(el "=") para el relleno. Como la entrada es un flujo de bytes que se codifica en grupos de 24 bits, le podrán faltar 0, 8 ó 16 bits, al igual que a la salida. Si la salida tiene la longitud adecuada, no hace falta relleno. Si a la salida le faltan 8bits, esto se corresponde con una salida de cuarto de dos bytes completos, un "short byte" y un byte faltante. El "short byte" se rellena con los 2 bits de orden inferior a cero. Los dos bytes faltantes se sustituyen con un carácter "=". Si a la salida le faltan 16 bits, esto se corresponde con una salida de cuarto de un byte completo, un "short byte" y dos bytes faltantes. El "short byte" se rellena con los 6 bits de orden inferior a cero. Los dos bytes faltantes se sustituyen con un carácter "=". Si se utilizaron "cero caracteres", el agente receptor no sería capaz de decir al decodificar el flujo de entrada si X'00' caracteres de cola en la última o en las dos últimas posiciones eran datos orelleno. Con caracteres de relleno, el número de "="s (0, 1 o 2) da la longitud del flujo de entrada en módulo 3(0, 2 ó 1 respectivamente).
La codificación "Base64" se puede traducir libremente de y a la forma "binary" sin ambigüedad ya que ambas tratan los datos como flujos de bytes. Esto se cumple también en el caso de la traducción de "Quoted-Printable" a cualquiera de las otras dos(en el caso de la conversión a "binary", se puede ver como un proceso con una traducción con una codificación "binary" intermedia), convirtiendo las secuencias de caracteres marcados a su forma de 8 bits, borrando los saltos de línea reversibles y sustituyendo los saltos de línea por secuencias <CRLF>. Esto no es estrictamente cierto para el proceso inverso ya que la codificación "Quoted-Printable" está orientada a registros: hay una diferencia entre un salto de línea y una secuencia "=0D=0A" embebida(por ejemplo, se mapearían de distinta forma en un sistema EBCDIC).
MIME no permite el anidamiento de codificaciones. Cualquier "Content-Type" que indique recursivamente otros campos Content-Type no puede usar un "Content-Transfer-Encoding" que no sea "7bit", "8bit" o "binary". Todas las codificaciones se deben hacer en el nivel más interno. El fin de esa restricción es simplificar el uso de los agentes de correo. Si no se permiten codificaciones anidadas, la estructura de todo el mensaje siempre le es visible para el agente sin tener que decodificar capas externas del mismo.
Esta simplificación para los agentes de correo tiene un precio: complejidad para las pasarelas. Como un agente puede especificar codificación "8bit" o "binary", una pasarela a una red en la que estas codificaciones no sean seguras tendrán que codificar el mensaje antes de pasárselo a la segunda red. La solución obvia, codificar el cuerpo del mensaje y cambiar el campo "Content-Transfer-Encoding:", no está permitida en los tipos "multipart" o "message" ya que violaría las restricciones indicadas más arriba. La pasarela, por tanto, debe descomponer el mensaje en sus componentes y recodificar las partes internar cuando sea necesaria.
Hay todavía otra restricción: en los tipos "message/partial" la codificación debe ser siempre "7bit"(no se permiten "8bit" y "binary"). La razón para esto es que si una pasarela necesita recodificar un mensaje, requiere disponer todo el mensaje, pero puede que no todas las partes del mismo estén disponibles(las partes se pueden transmitir en serie, debido a que la pasarela no sea capaz de almacenar todo el mensaje o incluso se pueden haber encaminado independientemente por diferentes pasarelas). Por ello, las partes de los cuerpos de los mensajes "message/partial" deben ser fiables hasta en el peor caso; es decir, deben codificarse en "7bit".
Todos los mecanismos estudiados arriba se refieren exclusivamente a los cuerpos, y no a las cabeceras. Los contenidos de las cabeceras de los mensajes aún se han de codificar en US - ASCII. En cabeceras que incluyan texto legible, este juego de caracteres no es apto para lenguajes distintos del inglés. Un mecanismo para incluir caracteres nacionales está definido en la segunda parte de MIME(RFC 1522). Este mecanismo difiere de la codificación "Quoted-Printable", que se usaría en el cuerpo del mensaje por las siguientes razones:
El enfoque de MIME es reservar secuencias improbables de caracteres ASCII legales que no son sintácticamente importantes en RFC 822. Las palabras de los campos de cabecera que tienen caracteres nacionales se reemplazan con palabras codificadas que tienen la forma:
=?charset?encoding?word?=
donde:
Una palabra codificada no debe tener caracteres en blanco embebidos(SPACE o TAB), puede tener hasta 75 caracteres, y puede no estar en una línea de más de 76 caracteres(sin contar <CRLF>). Estas reglas aseguran que las pasarelas no plegarán las palabras codificadas por el medio. Las palabras codificadas, en general, se pueden usar en las partes legibles de los campos de la cabecera. Por ejemplo, si un buzón se especifica de la forma:
The Octopus <octopus@garden.under.the.sea>
se podría utilizar una palabra codificada en la sección "The Octopus" pero no en la parte de dirección entre el "<" y el ">"). RFC 1522 especifica precisamente donde se pueden usar palabras codificadas en relación con la sintaxis RFC 822.
Se puede encontrar una descripción detallada de MIME en los siguientes RFCs:
Tabla de contenidos  REXEC ("Remote Execution Command Protocol")
REXEC ("Remote Execution Command Protocol")