 Tabla de contenidos
Tabla de contenidos  Consideraciones acerca de la coexistencia de TCP/IP y OSI
Consideraciones acerca de la coexistencia de TCP/IP y OSI Tabla de contenidos Consideraciones acerca de la coexistencia de TCP/IP y OSI
Internet ha crecido rápidamente en los últimos años, y en diciembre de 1994 albergaba más de 32000 redes que conectaban más de 3.8 millones de ordenadores en más de 90 países. Como un dirección de 32 bits proporciona unos 4 billones de posibles direcciones, da la impresión de el esquema de direccionamiento IP es más que suficiente para todos los hosts de Internet puesto que parece que aún es posible un incremento en mil veces la ocupación del espacio de direcciones. Desafortunadamente, no es este el caso, por una serie de razones, entre las que están las siguientes:
Estos factores implican que el espacio de direcciones está mucho más constreñido de lo que se supuso al principio. Este problema se denomina Agotamiento de las direcciones IP. Ya se están aplicando métodos para solucionarlo(ver El problema del agotamiento de las direcciones IP) pero al final, el espacio actual acabará por agotarse. El IETF("Internet Engineering Task Force") tiene un grupo de trabajo en ALE("Address Lifetime Expectations") con el fin de proporcionar estimaciones de cuándo el problema será intratable, y las estimaciones actuales fijan el agotamiento del espacio de direcciones entre el 2005 y el 2011. Antes de que esto ocurra, hará falta un sustituto para la versión actual de IP. Como además es posible que cambien las tendencias en e uso de IP, puede que esta sustitución sea necesaria para el año 2000. Es lo que se conoce como IP: La próxima generación(IPng) . La versión actual de IP es IPv4. La responsabilidad de la forma final de IPng la tiene el IPngD("IPng Directorate"). Hay otros grupos de trabajo en IP: IPNGREQ("IPng Requirements"), TACIT("Transition and Co-existence including Testing") y un grupo para candidato a IPng. Estos grupos son todos temporales y se espera que se disgreguen o que se fusionen con otros grupos de trabajo en otras áreas en las que el proceso de definición de IPng ya esté completo.
En julio de 1994, en un mitin del IETF en Toronto, el IPngAD("IPng Area Directors") del IETF presentó el RFC 1752 - Las recomendaciones para el protocolo IPng. Fue aprobado por el IETF en noviembre de 1994 y se convirtió en estándar propuesto.
Estos sucesos fueron la culminación de mucho trabajo y discusión que implicó a muchas partes interesadas.
El IPngD publicó el RFC 1550 - Solicitudes para IPng pidiendo requerimientos para IPng. Los requerimientos importantes se resumen aquí:
Hay tres propuestas principales para IPng:
CATNIP es un desarrollo de un viejo protocolo(TP/IX) que integra IPv4, Novell IPX y OSI CLNP("Connectionless Networking Protocol") y proporciona una infraestructura común. Se acerca en diseño a CLNP y enfatiza la facilidad de interoperabilidad con las implementaciones existentes de los tres. El paquete CATNIP contiene toda la información requerida por los tres protocolos en un formato comprimido usando una cabecera de 16 o más bytes. CATNIP usa una dirección de longitud variable. Las direcciones IPv4 existentes se mapean a direcciones de 7 bytes de las cuales sólo los últimos 4 bytes son la dirección IPv4. Los host IPv4 existentes deberían limitarse a interoperar de esta forma con los hosts CATNIP.
CATNIP se describe en el RFC 1707 - CATNIP: Una arquitectura común para Internet.
TUBA también se basa en CLNP; en pocas palabras, sustituye a IPv4 en la pila TCP/IP. Enfatiza las redes multiprotocolo. La transición entre IPv4 a IPng se hace usando una estrategia de pila dual. La pila de protocolo tiene dos capas de red independientes y cuando se intenta comunicar con otro host, un host de pila dual consulta al DNS sobre la dirección IP y el NSAP("Network Service Access Point") que es el equivalente CLNP. Si el DNS devuelve tanto la dirección IP como el NSAP, el host se comunica usando CLNP como protocolo de red.
TUBA se describe en el RFC 1347 - TUBA("TCP and UDP with Bigger Addresses"), una simple propuesta para el direccionamiento y el encaminamiento en Internet. Ver también el RFC 1526 - Asignación de identificadores de sistema para hosts TUBA/CLNP y el RFC 1561 - Uso de ISO CLNP en entornos TUBA.
SIPP es una combinación del trabajo de tres grupos de trabajo anteriores del IETF que dedicados al desarrollo de un IPng.
SIPP es un desarrollo evolutivo de IPv4. Enfatiza la eficiencia de operatividad en una gran variedad de tipos de red y la facilidad de interoperabilidad. Además del direccionamiento de 64 bits, incluye el concepto de direcciones extendidas usando una opción de encaminamiento: la longitud de la dirección efectiva puede ser cualquier múltiplo de 64.
SIPP se describe en el RFC 1710 - SIPP("Simple Internet Protocol Plus White Paper").
El IPngD("IPng Directorate") concluyó que las tres propuestas eran insuficientes para(CATNIP, TUBA y SIPP) para afrontar la lista aceptada de requirimientos, pero que SIPP, según como se define en el RFC 1710, era el que más se acercaba. Tras algunos cambios en el protocolo original, por ejemplo el uso de direcciones de 128 bits en vez de 64,, se decidió que SIPP era una base adecuada para IPng y que se le añadirían las características de otras propuestas para completar los restantes requerimientos. La solución propuesta se llamó IP Versión 6(IPv6).
Su definición sigue aún en progreso, y la información presentada aquí se basa en borradores. (6)
**** Aviso ****
Toda la información de la sección IP Versión 6 (IPv6) está sujeta a cambio y no se puede usar como referencia.
Se espera que la definición final de IPv6 se publique como series de estándares en RFCs.
**** Terminología ****
IPv6 usa el término paquete más que datagrama, pero el significado es el mismo, aunque los formatos sean distintos.IPv6 introduce un nuevo término, nodo, para un sistema que ejecuta IPv6, es decir, un host o un "router". Un host IPv6 es un nodo que no envía paquetes IPv6 que no estén dirigidos explícitamente a él. Un "router" es, como en IPv4, un nodo que envía paquetes no dirigidos explícitamente a él.
IPv6 incrementa la longitud de la cabecera IP de 20 a 40 bytes. La cabecera IPv6 contiene dos direcciones de 16 bytes(fuente y destino) precedidas de 8 bytes de control como se muestra en Figura - Cabecera IPv6. La cabecera IPv4 (ver Figura - Formato del datagrama IP) tiene dos direcciones de 4-byte precedidas de 12 bytes de control y seguidos posiblemente opciones. La reducción de la información de control y la eliminación de opciones de la cabecera tienen como fin optimizar el procesamiento del paquete. Los campos de uso poco frecuente que se han eliminado de la cabecera se han pasado a extensiones de cabecera opcionales.
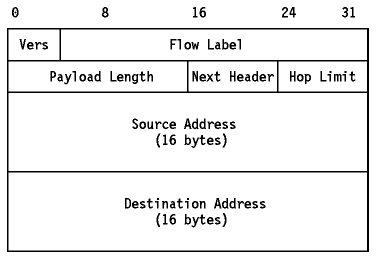
Figura: Cabecera IPv6
Los valores, excepto los dos últimos(que no estaban decididos en el momento de redactar el documento) figuran en el STD 2 - Números asignados de Internet, aunque la edición actual del STD 2(RFC 1700) menciona como protocolo tanto a SIP como a SIPP. Como se indicó antes, IPv6 es un desarrollo de estos dos protocolos.
Los distintos tipos de EH("extension header") se discuten brevemente más abajo.
Una comparación entre los formatos de las cabeceras de IPv4 y IPv6 muestra que los campos de IPv4 no tienen equivalente en IPv6.
Se espera que todos los nodos IPv6 determinen dinámicamente la PMTU("Path MTU") de cada enlace(como se describe en el RFC 1191 - Cáculo de PMTUs) y los nodos fuente sólo enviarán paquetes que no excedan el tamaño del PMTU. Por ello, los "routers" IPv6 no tendrán que fragmentar paquetes en mitad de rutas con más de un salto y permitirán hacer un uso mucho más eficiente de las rutas. En la actualidad está propuesto que cada enlace soporte una MTU de 576 bytes, pero este valor, como el resto de las especificaciones de IPv6, está sujeto a cambios.
Los EHs se sitúan entre la cabecera IPv6 y los datos destinados al protocolo de la capa superior. Se cuentan como parte de la carga efectiva de la trama. Cada cabecera tiene un campo de 8 bits, Next Header, que identifica el tipo de la cabecera siguiente. Todas las extensiones conocidas tienen este campo como el primer byte de la cabecera. La longitud de cada cabecera, que siempre es un múltiplo de 8 bytes, se codifica más tarde en el formato específico a ese tipo de cabecera. Existe un número limitado de EHs en IPv6, cualquiera de las cuales pueden aparecer sólo una vez en el paquete. Los nodos que originan paquetes deben tener las EHs en un orden específico, no así los que los reciben. Abajo se discuten brevemente los diversos tipo de EHs. Cuando el campo Next Header contiene un valor que no se corresponde con un EH significa el fin de las cabeceras IPv6 y el comienzo de los datos.
IPv6 permite la encapsulación de IPv6 en IPv6("tunneling"). Esto se hace con una valor 41 para el campo Next Header. El paquete IPv6 encapsulado puede tener sus propias EHs. Los "routers" no deberían añadir EHs a los paquetes. Sino encapsularlos en paquetes propio(fragmentados, si hace falta) ya que el tamaño de cada paquete se ha calculado en el nodo originador del mismo para que se ajuste al PMTU.
A excepción de la cabecera Hop by Hop(que debe seguir a la cabecera IP), los EHs sólo se procesan al final del trayecto.
IPv6 usa un formato común llamado TLV("Type-Length-Value") para campos de longitud variable hallados en las opciones Hop-by-Hop y End-to-End . Cada opción tiene una cabecera de 2 bytes seguida de los datos de la opción.
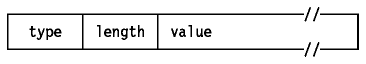
Figura: Formato TLV de IPv6
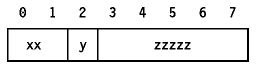
Para optimizar el rendimiento de las implementaciones de IPv6, las opciones individuales se alinean de forma que lo valores de varios bytes están situados dentro de sus límites naturales. En muchos casos, esto dará lugar a que estas cabeceras sean mayores de lo necesario, pero debería permitir a los nodos procesar los datagramas con mayor rapidez. Para conseguir esta alineación, todas las implementaciones de IPv6 deben reconocer dos opciones de relleno("padding"):
Una cabecera Hop-by-Hop contiene opciones que cada nodo que atraviesa el paquete debe examinar, además del nodo de destino. Debe seguir a la cabecera IPv6, y se identifica con el valor 0 en el campo Next Header de la cabecera IPv6. Este valor no es un número de protocolo sino un caso especial para distinguir este tipo único de EH y el valor 0 permanece reservado en el STD 2.
Inicialmente, no están definidas opciones Hop-by-Hop aparte de las de relleno.
Se identifica con el valor 43 en el campo Next Header precedente. Su primer byte es su campo Next Header y el segundo es el Routing Type. El único tipo definido inicialmente es el LSR("Loose Source Routing"), del mismo modo que en IPv4.
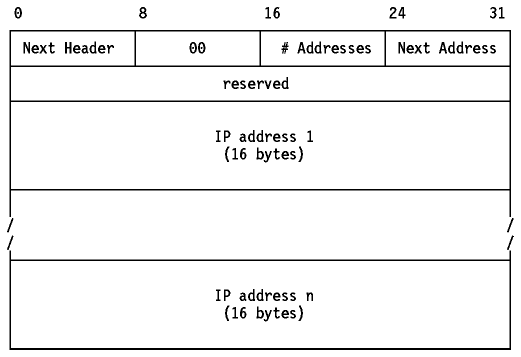
Figura: cabecera LSR de IPv6
Se identifica con 44 en el Next Header precedente.
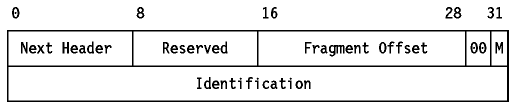
Figura: FH de IPv6
Se identifica con 51 en el Next Header precedente.

Figura: FH de IPv6
Tiene el mismo formato que la cabecera Hop-by-Hop, pero sólo lo examina el nodo de destino. Como sigue al RH, es independiente de cualquier opción de encaminamiento. De nuevo, sólo se especificamente inicialmente las opciones de relleno. El valor para el campo Next Header precedente no se ha definido aún.
IPv6 proporciona direcciones de 128 bits de longitud. A diferencia de IPv4, que tiene una organización basada estrictamente en las clases de direcciones, las direcciones IPv6 no están estructuradas así. Están diseñadas para ser usadas con CIDR("Classless InterDomain Routing"; ver CIDR("Classless Inter-Domain Routing")). El espacio de direcciones IPv6 es lo bastante grande como para acompasar un amplio rango de espacios de direcciones existentes y propuestos. La estrategia seguida, análoga a CIDR, consiste en utilizar parte de la dirección, por ejemplo el primer byte, para indicar el tipo de dirección. Estos tipos incluirían un mapeado del espacio IPv4 a IPv6, OSI NSAPs, Novell IPX, etc. Es más, la cabecera IPv6 permite encapsular información de direccionamiento arbitraria en cada paquete, lo que se podría utilizar para extender el mecanismo IPv6 a sistemas hipotéticos que no se pudieran mapear a IP.
IPv6 introduce el concepto de flow como una serie de paquetes relacionado desde una fuente a un destino que requiere un tipo particular de manipulación de mano de los "routers" implicados, por ejemplo para un servicio en tiempo real. La naturaleza de esa manipulación se puede implementar con opciones añadidas a los datagramas o con un protocolo separado.
Cada paquete IPv6 contiene una etiquete de flujo que es un campo de 28 bits:

Figura: Etiqueta de flujo de IPv6
Para tráfico sin control de flujo, el valor de Class se usa como prioridad cuando hay algún problema. Cuanto más bajo sea, menos ha de preocuparse el emisor de que el paquete llegue a su destino.
Las técnicas para convertir Internet de IPv4 a IPv6 se denominan en conjunto SIT("Simple Internet Transition"). SIT enfatiza la facilidad del proceso desde el punto de vista del administrador y del usuario. Las características de compatibilidad aseguran la protección de inversiones para los usuarios actuales de IPv4, las de interoperabilidad que la transición sea gradual y no impacte sobre la funcionalidad de Internet. La transición emplea las siguientes técnicas:
Las técnicas son adaptables a otros protocolos, notablemente, CLNP e IPX que tienen semánticas similares a nivel de red y con esquemas de direccionamiento fácilmente mapeables a IPv6.
El modelo de transición vislumbra la migración de diferentes organizaciones de forma independiente y en dos fases. La primera es una transición a una infraestructura dual IPv6/IPv4. La segunda, que no es obligatoria, es a una infraestructura sólo IPv6. Sólo se completa cuando no sea necesaria la interoperabilidad con IPv4.
La primera etapa es la más fácil de las dos, ya que todos los nodos soportan IPv4. La segunda requiere más esfuerzo, particularmente en la planificación e instalación de los "routers" que realizarán la traducción de cabeceras adecuada para que los nodos IPv6 interoperen con nodos IPv4.
Implica reemplazar el software de nodos sólo IPv4 por software IPv6/IPv4. Esto debería formar parte de los ciclos de distribución habituales, y los nodos IPv4 continuarían funcionando en modo compatible con IPv4.
Conceptualmente, el modelo de pila dual establece una duplicidad en los protocolos de la capa de red. Sin embargo, los cambios relacionados se necesitan obviamente en todas los protocolos de transporte para operar usando ambas pilas, y posiblemente en las aplicaciones, si se pretende que estas exploten las posibilidades de IPv6, como por ejemplo la mayor longitud de las direcciones.
Notación: las direcciones IPv6 se representan como una secuencia de 4 dígitos hexadecimales separados por comas. La secuencia 0000 se contrae como 0. Las direcciones IPv6 que se han de mapear a IPv4 se representan mejor como un prefijo IPv6 de 96 bits separado por comas y seguido de una dirección IPv4 en formato decimal separado por puntos, por ejemplo 0:0:0:0:0:ffff:9.180.214.114
Se definen tres tipos de direcciones IPv6:
Para el DNS se define un nuevo tipo de registro RR, AAAA, que indica una dirección IPv6. Los registros que el DNS encuentre en un nodo dependen del protocolo que se esté ejecutando.
Debido a que los nodos IPv6/IPv4 toman decisiones acerca de qué protocolos usar basadas en el tipo de dirección IPv6 del destino, la incorporación de registros AAAA al DNS es un prerrequisito para usar el DNS con IPv6. Esto no implica que los servidores de nombres tengan que usar pilas IPv6, sólo que soporten un tipo adicional de registro.
El que dos nodos puedan interoperar depende de sus capacidades y de sus direcciones:
La topología de encaminamiento de Internet se puede dividir en áreas de tal forma que cada área caiga en al menos dentro de uno de estos dos tipos:
Un área puede ser de ambos tipos, aunque el modelo se simplifica mucho si se cada área se trata sólo como uno de los dos tipos. Se emplean las siguientes reglas para la instalación de nodos que no usen pila dual:
Nota: Que un área sea de tipo IPv4-complete no significa que no se pueda usar encaminamiento IPv6 en ella, sólo que se usa encaminamiento IPv4 en su totalidad. Lo inverso es cierto en áreas tipo IPv6-complete.
Como se indicó arriba, la instalación de "routers" traductores de cabeceras es parte de la segunda fase de la transición. Por lo tanto, es improbable que las áreas IPv6-complete aparezcan inmediatamente en las organizaciones. Posiblemente, los controladores para la introducción de áreas IPv6-complete sean requerimientos para nuevos servicios que requieren IPv6, o para el agotamiento del espacio IPv4. La importancia de estos dos factores variará según la organización. Por ejemplo, las organizaciones comerciales con grandes redes IPv4 internas seguramente no se verán afectadas por el problema del agotamiento de las direcciones IPv4 a menos que lo experimenten dentro de sus propias redes.
El "tunneling" de paquetes IPv6 sobre IPv4 es muy simple; el paquete IPv6 se encapsula en un datagrama IPv4(que puede estar fragmentado).
Hay dos clases de "tunneling" de paquetes IPv6 sobre redes IPv4: automático y configurado.
Como el nombre indica, se realiza siempre que sea necesario. La decisión la toma un host IPv6/IPv4 que tiene un paquete que enviar a través de un área de tipo IPv4-complete, y sigue las siguientes reglas:
Nota: La dirección IP debe ser compatible con IPv4 para que se puede usar "tunneling". Las direcciones sólo IPv6 no son susceptibles de ser usadas ya que no se las puede direccionar con IPv4. Los paquetes de nodos IPv6/IPv4 a direcciones mapeadas a IPv4 no se "tunelizan" ya que se refieren a nodos sólo IPv4.
Las reglas anteriores enfatizan el uso de un "router" IPv6 con preferencia al "tunneling" por tres razones:
Un nodo no necesita conocer si está conectado a una área IPv6-complete o IPv4-complete: siempre que sea posible usará un "router" IPv6, y si no lo es usará "tunneling" (y en este caso deducirá que está conectado a un área IPv4-complete).
El "tunneling" automático puede ser host-a-host, o "router"-a-host. Un host fuente enviará un paquete IPv6 a un "router" IPv6 si es posible, pero puede que el "router" no pueda hacer lo propio, y en ese caso tendrá que hacer "tunneling". Debido a la preferencia de IPv6 sobre el "tunneling", los túneles serán siempre tan cortos como sea posible. Sin embargo, el túnel siempre se extiende por la ruta hasta el host de destino: como IPv6 usa el paradigma de encaminamiento de "saltos", un host no puede determinar si el paquete acabará por llegar a un área IPv6-complete antes de llegar al host de destino. Para evitar túneles que se extiendan por toda la ruta hasta el receptor, se emplea "tunneling" configurado. Hay una excepción a esta regla: como se describe en Traducción de cabeceras, todos los túneles terminan en "routers" que realizan traducción de cabeceras.
El mecanismo usado para el "tunneling" automático es muy simple.
Con una excepción ,descrita en Traducción de cabeceras, los "routers" IPv6/IPv4 intermedios nunca examinan los contenidos del paquete IPv6 encapsulado. El datagrama IPv4 se trata como si fuera un datagrama IPv4 normal y corriente.
Se utiliza para realizar "tunneling" host-router o router-router de IPv6-sobre-IPv4. El host emisor o el "router" retransmisor se configuran de tal forma que la ruta, además de contar con el siguiente salto, tiene una dirección de "fin de túnel"(que es siempre compatible con IPv4 ya que se debe tratar de un host IPv6/IPv4 accesible desde un área IP-complete). El proceso de encapsulación es el mismo que en modo automático exceptuando que la dirección IPv4 de destino no se calcula de los 32 bits inferiores de la dirección IPv6, sino de los 32 bits inferiores del fin de túnel. Cuando el "router" del fin del túnel recibe el datagrama, lo procesa como lo haría un nodo que estuviera al final de un túnel automático. Cuando el paquete IPv6 original para a la capa IPv6 del "router", este reconoce que no es el destinatario y lo retransmite como lo haría con cualquier paquete IPv6.
Puede ocurrir, por supuesto, que tras emerger de un túnel, el paquete entre nuevo en otro.
La traducción de cabeceras la requieren los nodos sólo IPv6 para interoperar con nodos sólo IPv4. Es una parte opcional de SIT. La llevan a cabo los "routers" IPv6/IPv4 dituados en las fronteras entre áreas IPv4-complete e IPv6-complete. El tráfico que cruza la frontera se clasifica de formas. Primero, el tráfico es:
Los "routers" traductores tienen que seleccionar la forma adecuada de direcciones IP, además de mapear correctamente las direcciones a traducir:
Hay un caso especial: el tráfico IPv6 "tunelizado". Si los traductores de cabeceras lo tratasen como tráfico IPv4 normal, el resultado sería un paquete IPv6 encapsulado en otro paquete IPv6. Por ello, los traductores han de examinar el número de protocolo de los datagramas IPv6, y si es 41(IPv6), desencapsularán el paquete en vez de traducir la cabecera IPv4. Efectivamente, los traductores de cabeceras siempre terminan los túneles.
Debido a este efecto, no es posible, en general, que un nodo IPv6/IPv4 envíe un paquete a un nodo con una dirección sólo IPv6 usando un túnel configurado a un "router" IPv6/IPv4 en la misma área IPv6-complete que el destino. Si se hiciera, el túnel podrían intersectar un área IPv6-complete de tránsito y el paquete se desencapsularía, terminando el túnel, y el paquete IPv6 no podría cruzar el área IPv4-complete debido a su dirección de destino sólo IPv6.
Para que un nodo IPv6/IPv4 envíe un paquete sólo IPv6 por medio de un "router" que soporte IPv4 en la misma área IPv6-complete que el destino, el paquete debe contener una ruta IPv6 especificada por la fuente consistente en el "router" IPv4 y el destino sólo IPv6. Este paquete tiene una dirección IPv4 compatible hasta que alcance el área IPv6-complete destino, para que pueda ser "tunelizado" seguramente a través de IPv4 con independencia de la topología.
Aunque el modelo topológico de SIT es simétrico, ya que su clasificación de los nodos es sólo IPv6, sólo IPv4, IPv4/IPv6, hay otros aspectos del diseño que no lo son:
 Resumen
Resumen