 Tabla de contenidos
Tabla de contenidos  Encaminamiento IP
Encaminamiento IP Tabla de contenidos Encaminamiento IP
Las direcciones de Internet pueden ser simbólicas o numéricas. La forma simbólica es más fácil de leer, por ejemplo: minombre@tcpip.com. La forma numérica es un número binario sin signo de 32 bits, habitualmente expresado en forma de números decimales separados por puntos. Por ejemplo, 9.167.5.8 es una dirección de Internet válida. La forma numérica es usada por el software de IP. La función de mapeo entre los dos la realiza el DNS(Domain Name System)discutido inDNS(Domain Name System). Primeramente examinaremos la forma numérica, denominada dirección IP.
Los estándares para las direcciones IP se describen en RFC 1166 -- Números de Internet.
Para ser capaz de identificar una máquina en Internet, a cada interfaz de red de la máquina o host se le asigna una dirección, la dirección IP, o dirección de Internet. Cuando la máquina está conectada a más de una red se le denomina "multi-homed" y tendrá una dirección IP por cada interfaz de red. La dirección IP consiste en un par de números:
IP dirección = <número de red<número de interfaz de red
La parte de la dirección IP correspondiente al número de red está administrada centralmente por el InterNIC(Internet Network Information Center)y es única en toda la Internet.(1)
Las direcciones IP son números de 32 bits representados habitualmente en formato decimal (la representación decimal de cuatro valores binarios de 8 bits concatenados por puntos). Por ejemplo128.2.7.9 es una dirección IP, donde 128.2 es el número de red y 7.9 el de la interfaz de red. Las reglas usadas para dividir una dirección de IP en su parte de red y de interfaz de red se explican abajo.
El formato binario para la dirección IP 128.2.7.9 es:
10000000 00000010 00000111 00001001
Las direcciones IP son usadas por el protocolo IP(ver Internet Protocol (IP)) para definir únicamente un host en la red. Los datagramas IP(los paquetes de datos elementales intercambiados entre máquinas) se transmiten a través de alguna red física conectada a la interfaz de la máquina y cada uno de ellos contiene la dirección IP de origen y la dirección IP de destino. Para enviar un datagrama a una dirección IP de destino determinada la dirección de destino de ser traducida o mapeada a una dirección física. Esto puede requerir transmisiones en la red para encontrar la dirección física de destino(por ejemplo, en LANs el ARP("Adress Resolution Protocol", analizado en ARP("Address Resolution Protocol"), se usa para traducir las direcciones IP a direcciones físicas MAC).
Los primeros bits de las direcciones IP especifican como el resto de las direcciones deberían separarse en sus partes de red y de interfaz.
Los términos dirección de red y netID se usan a veces en vez de número de red, pero el término formal, utilizado en RFC 1166, es número de red. Análogamente, los términos dirección de host y hostID se usan ocasionalmente en vez de número de host.
Hay cinco clases de direcciones IP. Se muestran en Figura - Clases asignadas de direcciones de Internet.
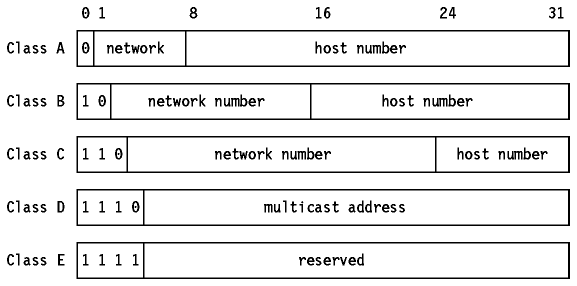
Figura - Clases asignadas de direcciones de Internet.
Nota: Dos de los números de red de cada una de las clases A, B y C, y dos de los números de host de cada red están preasignados: los que tienen todos los bits a 0 y los que tienen todos los bits a 1. Son estudiados más abajo en Direcciones IP especiales.
Es obvio que una dirección de clase A sólo se asignará a redes con un elevado número de hosts, y que las direcciones de clase C son adecuadas para redes con pocos hosts. Sin embargo, esto significa que las redes de tamaño medio(aquellas con más de 254 hosts o en las que se espera que en el futuro haya más de 254 hosts) deben usar direcciones de clase IP. El número de redes de tamaño pequeño y medio ha ido creciendo muy rápidamente en los últimos años y se temía que, de haber permitido que se mantuviera este crecimiento, todas las direcciones de clase B se habrían usado para mediados de los '90. Esto es lo que se conoce como el problema del agotamiento de las direcciones IP. Este problema y cómo está siendo tratado es analizado en El problema del agotamiento de las direcciones IP.
Un hecho a señalar en la división de la dirección IP en dos partes es que esta división a su vez divide en dos partes la responsabilidad de elegir una dirección IP. El número de red es asignado por el InterNIC y el de host por la autoridad que controla la red. Como veremos en la siguiente sección, el número de host puede dividirse aún más: esta división también es controlada por la autoridad propietaria de la red, y no por el InterNIC.
Debido al crecimiento explosivo de Internet, el uso de direcciones IP asignadas se volvió demasiado rígido para permitir cambiar con facilidad la configuración de redes locales. Estos cambios podían ser necesarios cuando:
Para evitar tener que solicitar direcciones IP adicionales en estos casos, se introdujo el concepto de subred.
El número de host de la dirección IP se subdivide de nuevo en un número de red y uno de host. Esta segunda red se denomina subred. La red principal consiste ahora en un conjunto de subredes y la dirección IP se interpreta como
<número de red<número de subred<número de host
La combinación del número de subred y del host suele denominarse "dirección local" o parte local". La creación de subredes se implementa de forma que es transparente a redes remotas. Un host dentro de una red con subredes es consciente de la existencia de estas, pero un host de un red distinta no lo es; sigue considerando la parte local de la dirección IP como un número de host.
La división de la parte local de la dirección IP en números de subred y de host queda a libre elección del administrador local; cualquier serie de bits de la parte local se puede tomar para la subred requerida. La división se efectúa empleando una máscara de subred que es un número de 32 bits. Los bits a cero en esta máscara indican posiciones de bits correspondientes al número de host, y los que están a uno, posiciones de bits correspondientes al número de subred. Las posiciones de la máscara pertenecientes al número de red se ponen a uno pero no se usan. Al igual que las direcciones IP, las máscaras de red suelen expresarse en formato decimal.
El tratamiento especial de "todos los bits a cero" y "todos los bits a uno" se aplica a cada una de las tres partes de dirección IP con subredes del mismo modo que a una dirección IP que no las tiene. Ver Direcciones IP especiales. Por ejemplo, una red de clase B con subredes, que tiene un parte local de 16 bits, podría hacer uso de uno de los siguientes esquemas:
Mientras el administrados es totalmente libre de asignar la parte de subred a la dirección local de cualquier forma legal, el objetivo es asignar un número de bits al número de subred y el resto a la dirección local. Por tanto, es corriente usar un bloque de bits contiguos al comienzo de la parte local para el número de subred ya que así las direcciones son más legibles(esto es particularmente cierto cuando la subred ocupa 8 o 16 bits). Con este enfoque, cualquiera de las máscaras anteriores es buena, pero no máscaras como 255.255.252.252 o 255.255.255.15.
Hay dos tipos de "subnetting": estático y de longitud variable. El de longitud variable es el más flexible de los dos. El tipo de "subnetting" disponible depende del protocolo de encaminamiento en uso; el IP nativo sólo soporta "subnetting" estático, al igual que el ampliamente utilizado RIP. Sin embargo, la versión 2 del protocolo RIP soporta además "subnetting" de longitud variable. Para ver una descripción de RIP y RIP2, ir a RIP("Routing Information Protocol"). Protocolos de encaminamiento analiza los protocolos de encaminamiento en detalle.
El "subnetting" estático consiste en que todas las subredes de la red dividida empleen la misma máscara de red. Esto es simple de implementar y de fácil mantenimiento, pero implica el desperdicio de direcciones para redes pequeñas. Por ejemplo, una red de cuatro hosts que use una máscara de subred de 255.255.255.0 desperdicia 250 direcciones IP. Además, hace más difícil reorganizar la red con una máscara nueva. Hoy en día, casi todos los hosts y "routers" soportan "subnetting" estático.
Cuando se utiliza "subnetting" de longitud variable, las subredes que constituyen la red pueden hacer uso de diferentes máscaras de subred. Una subred pequeña con sólo unos pocos hosts necesita una máscara que permita acomodar sólo a esos hosts. Una subred con muchos puede requerir una máscara distinta para direccionar esa elevada cantidad de hosts. La posibilidad de asignar máscaras de subred de acuerdo a las necesidades individuales de cada subred ayuda a conservar las direcciones de red. Además, una subred se puede dividir en dos añadiendo un bit a la máscara. El resto de las subredes no se verán afectadas por el cambio. No todos los hosts y "routers" soportan "subnetting" de longitud variable.
Sólo se dispondrán redes del tamaño requerido y los problemas de encaminamiento se resolverán aislando las redes que soporten "subnetting" de longitud variable. Un host que no soporte este tipo de "subnetting" debería disponer de una ruta de encaminamiento a un "router" que sí lo haga.
A primera vista, parece que la presencia de un host que sólo puede manejar "subnetting" estático impediría utilizar "subnetting" de longitud variable en cualquier punto de la red. Afortunadamente no es este el caso. Siempre que los "routers" entre las subredes que tengan distintas máscaras usen "subnetting" de longitud variable, los protocolos de encaminamiento son capaces de ocultar la diferencia entre máscaras de subred a cada host de una subred. Los hosts pueden seguir usando encaminamiento IP básico y desentenderse de las complejidades del "subnetting", que quedan a cargo de "routers" dedicados a tal efecto.
Asumamos que a nuestra red se le ha asignado el número de red IP de clase B 129.112. Tenemos que implementar múltiples redes físicas en nuestra red, y algunos de los "routers" que usaremos no admiten "subnetting" de longitud variable. Por tanto tendremos que elegir una máscara de subred para la totalidad de la red. Tenemos una dirección local de 16 bits para la red y debemos dividirla correctamente en dos partes. Por el momento, no preveremos tener más de 254 redes físicas, ni más de 254 hosts por red, de tal forma que una máscara de subred aceptable sería 255.255.255.0(que además tiene la ventaja de ser legible). Esta decisión debe tomarse cuidadosamente, ya que será difícil cambiarla posteriormente. Si el número de redes o de hosts crece por encima de nuestras previsiones, puede que tengamos que implementar "subnetting" de longitud variable para usar al máximo las 65534 direcciones locales de las que disponemos.
Figura - Una configuración de subred muestra un ejemplo de implementación con tres subredes.

Figura: Una configuración de subred - Tres redes físicas forman una sola red IP. Los dos "routers" realizan tareas ligeramente diferentes. El "router" 1 actúa como "router" entre las subredes 1 y 3 así como para toda nuestra red y el resto de Internet. El "router" 2 actúa sólo como "router" entre las redes 1 y 2.
Consideremos ahora una máscara de subred diferente: 255.255.255.240. El cuarto octeto se ha dividido por tanto en dos partes:
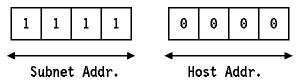
La siguiente tabla contiene las posibles subredes que usarían esta máscara:

Tabla: Valores de subredes para la máscara de subred 255.255.255.240
Para cada uno de estos valores de subred, sólo 14 direcciones( de la 1 a la 14) de hosts están disponibles, ya que sólo la parte derecha del octeto se puede usar y porque las direcciones 0 y 15 tienen un significado especial tal como se describe en Direcciones IP especiales.
De este modo, el número de subred 9.67.32.16 contendrá a los hosts cuyas direcciones IP estén en el rango de 9.67.32.17 a 9.67.32.30, y el número de subred 9.67.32.32 a los hosts cuyas direcciones IP estén en el rango de 9.67.32.33 a 9.67.32.46, etc.
Para encaminar un datagrama IP en la red, el algoritmo general de encaminamiento IP tiene la forma siguiente:
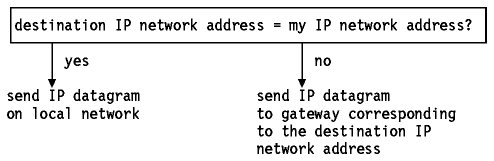
Figura: Encaminamiento IP con subredes
Para ser capaz de distinguir entre subredes, el algoritmo de encaminamiento IP cambia y adopta la siguiente forma:
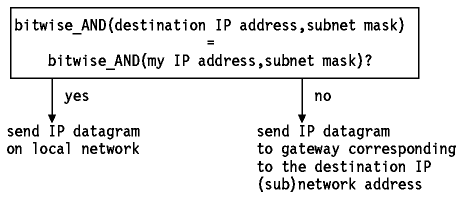
Figura: Encaminamiento IP con subredes
Algunas consecuencias de este algoritmo son:
En caso de que uno o más hosts no soporten "subnetting", una forma alternativa de lograr el mismo objetivo es hacer uso del proxy-ARP, que no requiere cambios al algoritmo de encaminamiento IP para un host con una sola interfaz("single-homed"), pero requiere cambios en los "routers" entre subredes. Esto se explica con más detalle en Proxy-ARP o "subnetting" transparente.
Habitualmente, los hosts almacenan su máscara de subred en un fichero de configuración. Sin embargo, a veces esto no se puede hacer, como es el caso de estaciones de trabajo sin disco. El protocolo ICMP incluye dos mensajes, solicitud de máscara de direcciones y respuesta de máscara de direcciones, que permitirá a los hosts obtener la máscara de subred correcta de un servidor. Ver Solicitud de máscara de direcciones(17) y Respuesta de máscara de direcciones (18) para más información.
Un host se denomina "multi-homed" cuando tiene conexión física con múltiples redes o subredes . Todos los "routers" han de ser multi-homed ya que su trabajo es unir redes o subredes distintas. Un host multi-homed tiene siempre una dirección IP diferente para cada adaptador de red, puesto que cada adaptador se halla en una red distinta.
Hay una excepción aparente a esta regla: con algunos sistemas(por ejemplo VM y VMS) es posible especificar la misma dirección IP para múltiples enlaces punto a punto (como es el caso de los adaptadores de canal a canal) si el protocolo de encaminamiento se limita al algoritmo básico de encaminamiento IP.
Como se ha señalado anteriormente, cualquier componente de un dirección IP con todos sus bits a 1 o a 0 tiene un significado especial
Hay otra dirección de especial importancia: el número de red de clase A con todos los bits a 1, 127, se reserva para la dirección de loopback. Todo lo que se envíe a una dirección con 127 como valor del byte de mayor orden, por ejemplo 127.0.0.1, no debe encaminarse a través de la red, sino directamente del controlador de salida al de entrada. (2)
La mayoría de las direcciones IP se refieren a un sólo destinatario: se denomina direcciones de unicast. Sin embargo, como se ha señalado anteriormente, hay dos tipos especiales de direcciones IP que se utilizan para direccionar a múltiples destinatarios: las direcciones de broadcast y de multicast. Cualquier protocolo no orientado a conexión puede enviar mensajes de broadcast o de multicast, además de los unicast. Un protocolo orientado a conexión sólo puede usar direcciones de unicast porque la conexión existe entre un par específico de hosts. Ver TCP("Transmission Control Protocol") para más información sobre los protocolos orientados a conexión..
Hay una serie de direcciones que usan para el broadcast en IP: todas manejan el convenio de que "todos los bits a 1" indica "todos". Las direcciones de broadcast nunca son válidas como direcciones fuente, sólo como direcciones de destino. Los diferentes tipos de broadcast se listan aquí:
Si los "router" respetan todos los mensajes de broadcast dirigidos a subredes, utilizan un algoritmo llamado Retransmisión Inversa("Reverse Path Forwarding") para evitar que los mensajes de broadcast se multipliquen descontroladamente. Ver el RFC 922 para más detalles sobre este algoritmo.
El broadcast tiene una gran desventaja: su falta de selectividad. Si un datagrama IP se difunde por broadcast a una subred, cada host de la misma lo recibirá, y tendrá que procesarlo para determinar si el destinatario está activo. Si no lo está, el datagrama IP se elimina. El multicast elimina este overhead al usar grupos de direcciones IP.
Cada grupo está representado por un número de 28 bits, incluido en una dirección de clase D. Recordar que una dirección de clase D tiene el formato:

Hay dos clases de grupos de hosts:
Algunos otros ejemplos usados por el protocolo de encaminamiento OSPF(ver Versión 2 de OSPF("Open Shortest Path First Protocol")) son:
Una aplicación puede además determinar la dirección IP permanente de un grupo por medio del DNS (ver DNS("Domain Name System")) usando el dominio mcast.net, o determinar el grupo permanente para una dirección a través de una consulta por punteros(ver Mapeando direcciones IP a nombres de dominio - Consultas por punteros) en el dominio 224.in-addr.arpa. Un grupo permanente existe aunque no tenga miembros.
El multicast en una sola red física que lo soporte s simple. Para unirse a un grupo, un proceso activo en un host debe informar de algún modo a sus controladores de red que desea ser parte del grupo especificado. El propio software de los controladores debe mapear la dirección de multicast a una dirección física de multicast para permitir la recepción de paquetes en esa dirección. Además, tiene que asegurarse de que el proceso receptor no recibe datagramas espúreos, chequeando la dirección de destino de la cabecera IP antes de pasarlos a la capa IP.
Por ejemplo, Ethernet soporta multicast si el byte de orden superior de la dirección de 48 bytes es X'01' y además IANA posee un bloque de la dirección, consistente en las direcciones entre X'00005E000000' y X'00005EFFFFFF'. IANA ha asignado la mitad inferior de este rango para direcciones de multicast, de modo que en una LAN Ethernet hay un rango de direcciones físicas entre X'01005E000000' y X'01005E7FFFFF' usado para el multicast IP. Este rango tiene 23 bits utilizables, por lo que las direcciones de multicast de 28 bits se mapean a Ethernet tomando los 23 bits inferiores, es decir, hay 32 direcciones de multicast mapeadas sobre cada dirección Ethernet. Debido a este mapeo no unívoco, hace falta efectuar un filtrado en el controlador. Hay otras dos razones por la que se podría seguir necesitando el filtrado:
A pesar de la necesidad de filtrar por software de paquetes multicast, el multicast aún causa mucho menos overhead en los hosts no interesados. En particular, aquellos hosts que no estén en ningún grupo no escuchan a los mensajes con direcciones multicast y por tanto todos los mensajes multicast son filtrados por el hardware de la interfaz de red.
El multicast no se limita a una sola red física. Hay dos aspectos del multicast en redes físicas a considerar:
El primer problema tiene fácil solución: el datagrama multicast tiene un TTL(tiempo de vida o "Time To Live") como cualquier otro datagrama, que se decrementa con cada salto a una nueva red Cuando el TTL se decrementa a cero, el datagrama no puede ir más lejos. El mecanismo para decidir si un router debe enviar un datagrama multicast se denomina IGMP("Internet Group Management Protocol" o "Internet Group Multicast Protocol"). IGMP se describe más detalle en IGMP("Internet Group Management Protocol"). IGMP y el multicast se definen en el RFC 1112 - Extensiones de host para el multicast IP.
El número de redes en Internet se ha ido doblando aproximadamente cada año durante varios años. Sin embargo, el uso de las redes de clase A, B y C difiere mucho: la mayoría de las redes asignadas a finales de 1980 eran de clase B, y en 1990 se hizo evidente que, de continuar si la tendencia, el último número de red de clase B sería asignado en 1994. Por otro lado, las redes de clase C apenas se usaban.
La razón de esta tendencia era que la mayoría de los usuarios potenciales hallaban a las redes de clase B lo bastante grandes para sus necesidades previstas, ya que acomoda hasta 65534 hosts, mientras que un red de clase C, con un máximo de 254 hosts, restringe considerablemente el crecimiento potencial de hasta las redes pequeñas. Es más, la mayoría de las redes de clase B estaban asignadas a redes pequeñas. Hay un número relativamente pequeño de redes que necesiten 65,534 direcciones de hosts, pero muy pocas para las 254 sea un límite adecuado. En resumen, aunque las divisiones de clase A, B y C de las direcciones IP son lógicas y fáciles de usar(puesto que se producen a nivel de byte), en perspectiva no son las más prácticas, ya que las redes de clase C son demasiado pequeñas para la mayoría de las organizaciones mientras son demasiado grandes para ser bien aprovechadas por nadie excepto por las organizaciones más grandes.
Tabla - uso de las direcciones de red IP entre 1990 y 1994 muestra el uso de las direcciones de red IP entre 1990 y 1994.
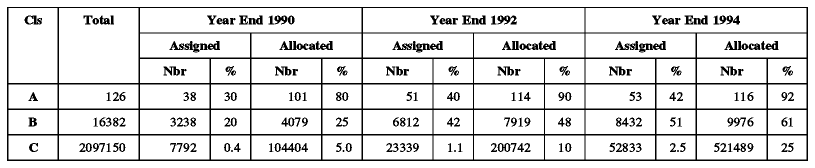
Tabla: uso de las direcciones de red IP entre 1990 y 1994. - Fuente: netinfo/ip_network_allocations.95Jan del FTP rs.internic.net
Algunos aspectos de esta tabla requieren explicación.
Nota: Según IANA, el estado de un red es asignado o reservado, pero esta tabla trata el estado reservado como un superconjunto del asignado; el porcentaje real se puede calcular restando de 100 el porcentaje reservado para determinar cuánto espacio "libre" queda.
Otra forma de ver estos datos es examinar la proporción del espacio de direcciones que ha sido usado: las cantidades de la tabla no muestran, por ejemplo, que el espacio de direcciones de clase A es tan grande como el de las clases B y C combinados, o que teóricamente una sola red de clase A puede tener tantos host como 66,000 redes de clase C. Figura - Uso del espacio de direcciones IP muestra el uso del espacio de direcciones desde este punto de vista. El gráfico representa un espacio de direcciones de 32 bits, es decir, 4,294,967,296 direcciones. Las direcciones de clase A, B y C se dividen del modo siguiente:
Se muestra en porciones resaltadas: el área resultante de unir todas las porciones representa la proporción del espacio de direcciones IP en uso.
El espacio reservado se muestra con porciones sombreadas.
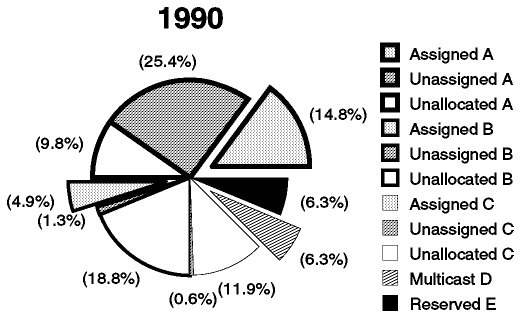
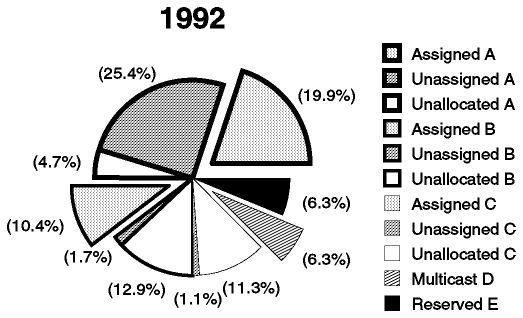
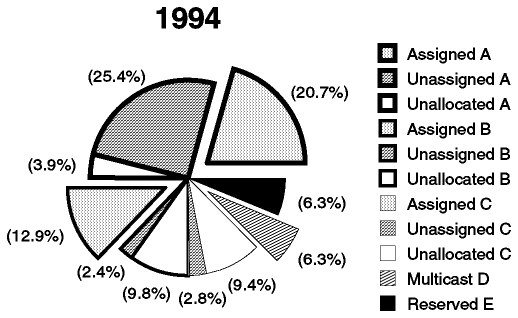
Figura: Uso del espacio de direcciones
Si se examina Tabla - Uso de las direcciones IP entre 1990 y 1994 se verá que es de 1990, el número de redes asignadas de clase B se ha ido incrementado a una tasa mucho más baja que el número total de redes asignadas y que el agotamiento previsto de los números de clase B. La razón es que la política del InterNIC sobre la concesión de números de red cambió en desde 1990 para preservar el espacio de direcciones existente, en particular para frenar el agotamiento del espacio de direcciones de clase B. Las nuevas políticas se pueden resumir en:
y
Cualquier solicitud de una red de clase A se trataría considerando estrictamente el caso particular.
Los rangos definidos como "otros" se utilizan donde hace falta flexibilidad por encima de las limitaciones de las fronteras regionales. El rango definido como "multi-regional" incluye las redes de clase C que habían sido asignadas antes de que se adoptase este nuevo esquema. El InterNIC asignó 192 redes, y 193 habían sido previamente reservadas para el RIPE en Europa.
La mitad superior del espacio de direcciones de clase C(208.0.0 a 223.255.255) permanece sin asignar y sin reservar.
El número máximo de números de red asignados contiguamente es 64, correspondiente a un prefijo de 18 bits. Una organización que requiera más de 4096 direcciones pero menos de 16,384 puede solicitar tanto una clase B como un rango de direcciones de clase C. En general, el número de clases C asignadas es el mínimo necesario para proporcionar la cantidad requerida de direcciones IP a la organización partiendo de una previsión sobre el plazo de los dos años siguientes. Sin embargo, en algunos casos, una organización puede solicitar múltiples redes que sean tratadas por separado. Por ejemplo, a una organización con 600 hosts se le asignarían normalmente 4 redes de clase C. No obstante, si esos hosts estuvieran distribuidos a lo largo de 10 LANs en anillo con testigo con entre 50 y 70 hosts por LAN, tal esquema de direcciones causaría graves problemas, ya que la organización tendría que encontrar 10 subredes dentro de un rango de direcciones locales de 10 bits. Esto significaría que al menos alguna de las LAN tendría una máscara de subred de 255.255.255.192, que sólo permite 62 hosts por LAN. La intención de las reglas no es forzar a la organización a que tenga un complicado sistema de subredes, así que la organización debería solicitar 10 números de clase C diferentes, uno para cada LAN.
Las reglas actuales se pueden encontrar en el RFC 1466 - Directrices para la gestión del espacio de direcciones IP. Las razones de las reglas de distribución de los números de red de clase C quedarán patentes en la próxima sección. Usar números de clase C de esta forma ha frenado el problema del agotamiento de las direcciones de clase B, pero no es una solución definitiva a las limitaciones de espacio inherentes a IP. La solución a largo plazo se discute en IP: La próxima generación(IPng).
Otro enfoque de la conservación del espacio de direcciones IP se describe en el RFC 1597 - Distribución de direcciones para redes privadas. En pocas palabras, relaja la regla de que las direcciones IP han de ser unívocas globalmente al reservar parte del espacio de direcciones para redes que se usan exclusivamente dentro de una sola organización y que no requieren conectividad IP con Internet. Hay tres rangos de direcciones que IANA ha reservado con este propósito:
Cualquier organización puede usar cualquier dirección en estos rangos si no hace referencia a ninguna otra organización. Sin embargo, debido a que estas direcciones no son unívocas a nivel global, no pueden ser direccionadas por hosts de otras organizaciones y no están definidas para los "routers" externos. Se supone que los "routers" de una red que no usa direcciones privadas, particularmente aquellos operados por proveedores de servicios de Internet, han de desechar toda información de encaminamiento relativa a estas direcciones. Los "router" de una organización que utiliza direcciones privadas deberían limitar todas las referencias a direcciones privadas a los enlaces internos; no deberían hacer públicas las rutas a direcciones privadas ni enviar datagramas IP con estar direcciones a los "routers" externos. Los hosts que sólo tienen una dirección IP privada carecen de conexión IP con Internet. Esto puede ser deseable y a lo mejor puede ser una razón para emplear direcccionamiento privado. Toda la conectividad con host externos de Internet la deben proporcionar pasarelas de aplicación.
El uso de un rango de direcciones de clase C en vez de una sola de clase B acarrea un gran problema: cada red ha de ser direccionada por separado. El encaminamiento IP estándar sólo comprende las clases A, B y C. Dentro de cada uno de estos tipos de red, se puede usar "subnetting" para proporcionar mejor granularidad del espacio de direcciones en cada red, pero no hay forma de especificar que existe una relación real entre múltiples redes de clase C. El resultado de esto se denomina el problema de la explosión de la tabla de encaminamiento: una red de clase B de 3000 host requiere una entrada en la tabla de encaminamiento para cada "router" troncal, pero si la misma red se direccionase como un rango de redes de clase C, requeriría 16 entradas.
La solución a este problema es un método llamado CIDR("Classless Inter-Domain Routing"). El CIDR es un protocolo propuesto como estándar con status electivo.
El CIDR no encamina de acuerdo a la clase del número de red(de ahí el término "classless": sin clase) sino sólo según los bits de orden superior de la dirección IP, que se denominan prefijo IP. Cada entrada de encaminamiento CIDR contiene una dirección IP de 32 bits y una máscara de red de 32 bits, que en conjunto dan la longitud y valor del prefijo IP. Esto se puede representar como <dir_IP máscara_red. Por ejemplo, <194.0.0.0 254.0.0.0 representa el prefijo de 7 bits B'1100001'. CIDR maneja el encaminamiento para un grupo de redes con un prefijo común con una sola entrada de encaminamiento. Esta es la razón por la que múltiples números de red de clase C asignados a una sola organización tienen un prefijo común. Al proceso de combinar múltiples redes en una sola entrada se le llama agregación de direcciones o reducción de direcciones. También se le llama supernetting poque el encaminamiento se basa en máscaras de red más cortas que la máscara de red natural de la dirección IP, en contraste con el subnetting, donde las máscaras de red son más largas que la máscara natural.
A diferencia de las máscaras de subred, que normalmente son contiguas pero pueden tener una parte local no contigua, las máscaras de superred son siempre contiguas
Si se representan las direcciones IP con una árbol que muestre la topología de encaminamiento, donde cada hoja del árbol significa un grupo de redes que se consideran como una sola unidad(llamada dominio de encaminamiento) y el esquema de direccionamiento IP se elige de modo que cada bifurcación del árbol corresponda a un incremento en la longitud del prefijo IP, entonces el CIDR permite realizar la agregación de direcciones muy eficientemente. Por ejemplo, si un "router" en Norteamérica encamina todo el tráfico europeo a través de un único enlace, entonces una sola entrada de encaminamiento para <194.0.0.0 254.0.0.0 incluye el grupo de direcciones de redes de clase C asignadas a Europa como se describe más arriba. Esta única entrada toma el lugar de todas las entradas de los números de red asignados, que son un máximo de 2exp17, o 131,072. En el extremo europeo del enlace, hay entradas de encaminamiento con prefijos más largos que mapean la topología de la red europea, pero esta información de encaminamiento no hace falta en el extremo americano. La filosofía de CIDR es "la mejor aproximación es la que tiene más aciertos", de modo que si los US necesitan hacer una excepción para un rango de direcciones, como por ejemplo las 64 redes <195.1.64.0 255.555.192.0, necesita sólo una entrada adicional, que en la tala de encaminamiento se superpone a otras entradas más generales(más cortas) de las redes que contiene. De este ejemplo se hace evidente que a medida que aumenta el uso del espacio de direcciones IP, particularmente de las de clase C, los beneficios de CIDR aumentan por igual, siempre que la asignación de direcciones siga la topología de la red. El estado actual del espacio de direcciones IP no sigue este esquema ya que el desarrollo de CIDR fue posterior. Sin embargo, se están asignando nuevas direcciones de clase C de tal modo que sean compatibles con CIDR, lo que debería tener el efecto de aliviar el problema de la explosión de las tablas de encaminamiento a corto plazo. A largo plazo, puede que sea necesaria una reestructuración del espacio de direcciones IP siguiendo pautas topológicas. Esto supondría tener que renumerar un gran número de redes, implicando un enorme trabajo de implementación, por lo que se trataría de un proceso gradual
Asumir que la topología de encaminamiento se puede representar con un simple árbol es un exceso de simplificación; aunque la mayoría de los dominios de encaminamiento tienen un sólo enlace que proporciona acceso al resto de Internet, hay también muchos dominios con enlaces múltiples. Los dominios de encaminamiento de estos dos tipos se llaman "single-homed"(unipuerto) y "multi-homed"(multipuerto). Es más, la topología no es estática. No sólo se unen nuevas organizaciones a un ritmo creciente, sino que las ya existentes pueden cambiar partes de su topología, por ejemplo, si cambian de proveedor de servicios por razones comerciales o de otra índole. Aunque estos casos complican la implementación práctica del encaminamiento basado en CIDR y reducen la eficiencia de la agregación de direcciones que se puede conseguir, la estrategia no deja de ser válida.
Las políticas actuales para la distribución de direcciones de Internet y las suposiciones en las que se basan se describen en el RFC 1518 - Una arquitectura para la distribución de direcciones IP con CIDR. Se pueden resumir en:
Nota: Esto implica que si una organización cambia su proveedor de servicios de Internet, debería cambiar todas sus direcciones IP. Esto no es lo habitual, pero es probable que la difusión de CIDR lo convierta en una práctica mucho más común.
Debido a que los dominios "multi-homed" varían mucho en su carácter y ninguno de los esquemas anteriores parece apropiado para todos, no existe una política que sea la mejor, y el RFC 1518 no especifica ninguna regla para elegir entre ellas.
La implementación de CIDR en Internet se basa fundamentalmente en BGP("Border Gateway Protocol", versión 4) (ver BGP-4("Border Gateway Protocol", versión 4)). En el futuro CIDR también se implementará con una variante del estándar ISO IDRP, ISO 10747("Inter-Domain Routing Protocol"), llamado IDRP para IP, que está estrechamente relacionado con BGP-4.
La estrategia de implementación, descrita en el RFC 1520 - Intercambiando información de encaminamiento a través de las fronteras de los proveedores en el entorno CIDR, implica un proceso por fases a través de la jerarquía de encaminamiento, empezando por los "routers" troncales. Los proveedores de servicios de red se dividen en cuatro tipos:
La implementación de CIDR implica una primera fase por medio de los proveedores de tipo 0, luego los de tipo 2 y finalmente los de tipo 3. CIDR ya se ha instituido ampliamente en troncales y más de 9000 rutas se han reemplazado por aproximadamente 2000 rutas CIDR.
El protocolo DNS es un protocolo estándar (STD 13). Su status es recomendado. Es descrito en:
Las configuraciones iniciales de Internet requerían que los usuarios emplearan sólo direcciones IP numéricas. Esto evolucionó hacia el uso de nombres de host simbólicos muy rápidamente. Por ejemplo, en vez de escribir TELNET 128.12.7.14, se podría escribir TELNET eduvm9, y eduvm9 se traduciría de alguna forma a la dirección IP 128.12.7.14. Esto introduce el problema de mantener la correspondencia entre direcciones IP y nombres de máquina de alto nivel de forma coordinada y centralizada.
Inicialmente, el NIC("Network Information Center") mantenía el mapeado de nombres a direcciones en un sólo fichero(HOSTS.TXT) que todos los hosts obtenían vía FTP. Se denominó espacio de nombres plano.
Debido al crecimiento explosivo del número de hosts, este mecanismo se volvió demasiado tosco(considerar el trabajo necesario sólo para añadir un host a Internet) y fue sustituido por un nuevo concepto: DNS("Domain Name System"). Los hosts pueden seguir usando un espacio de nombres local plano(el fichero HOSTS.LOCAL) en vez o además del DNS, pero fuera de redes pequeñas, el DNS es prácticamente esencial. El DNS permite que un programa ejecutándose en un host le haga a otro host el mapeo de un nombre simbólico de nivel superior a una dirección IP, sin que sea necesario que cada host tenga una base de datos completa de los nombres simbólicos y las direcciones IP.
En el resto de esta sección examinaremos cómo funciona el DNS desde el punto de vista del usuario. Ver DNS("Domain Name System") para más detalles sobre la implementación y los tipos de datos almacenados en DNS.
Consideremos la estructura interna de una gran organización. Como el jefe no lo puede hacer todo, la organización tendrá que partirse seguramente en divisiones, cada una de ellas autónoma dentro de ciertos límites. Específicamente, el ejecutivo a cargo de una división tiene autoridad para tomar decisiones sin requerir el permiso de su jefe.
Los nombres de dominio se forman de modo similar, y con frecuencia reflejarán la delegación jerárquica de autoridades usada para asignarlos. Por ejemplo, considerar el nombre
lcs.mit.edu
Aquí, lcs.mit.edu es el nombre de dominio de nivel inferior, un subdominio de mit.edu, que a su vez es un subdominio de edu("education"), conocido como dominio raíz. También podemos representar este forma de asignar nombres con un árbol jerárquico,(ver Figura - Espacio de nombres jerárquico).
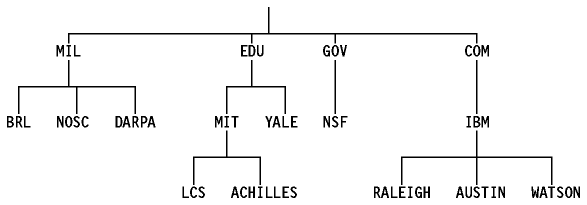
Figura: Espacio de nombres jerárquico - Esta figura muestra la cadena de autoridades en la asignación de nombres de dominio. Este árbol es sólo una fracción mínima del espacio de nombres real.
Figura - Los dominios genéricos de la cima muestra algunos de los dominios de la cima. El dominio único que se halla sobre la cima no tiene nombre y se le conoce como dominio raíz. La estructura completa se explica en las siguientes secciones.
Cuando se usa el DNS, es común trabajar con sólo una parte de la jerarquía de dominios, por ejemplo el dominio ral.ibm.com. El DNS proporciona un método sencillo para minimizar la cantidad de caracteres a escribir en estos casos. Si el nombre de dominio termina en un punto(por ejemplo wtscpok.itsc.pok.ibm.com.) se asume que está completo. Es lo que se llama un FQDN("Fully Qualified Domain Name") o nombre absoluto de dominio. Si, sin embargo, no termina en punto,(por ejemplo wtscpok.itsc) estará incompleto y procesador de nombres del DNS, como se verá más abajo, podrá completarlo, por ejemplo, añadiendo un sufijo como .pok.ibm.com al nombre de dominio. Las reglas para hacer esto dependen de la implementación y son configurables localmente.
A los tres dominios de la cima se les llama dominios genéricos u organizacionales.
Figura: Los dominios genéricos de la cima
Puesto que Internet comenzó en los Estados Unidos, la estructura del espacio de nombres jerárquico tenía inicialmente sólo organizaciones estadounidenses en la cima de la jerarquía, y sigue siendo cierto que gran parte de las organizaciones de la cima de la jerarquía son estadounidenses. Sin embargo, sólo los dominios .gov y .mil están restringidos a los US.
Además hay dominios de nivel de cima para cada uno de los códigos internacionales de dos caracteres ISO 3166 para países(de ae para los Emiratos Árabes Unidos a zw para Zimbabwe). Se les conoce como dominios de países o dominios geográficos. Muchos países tienen sus propios dominios de segundo nivel por debajo, paralelamente a los dominios genéricos. Por ejemplo, en el Reino Unido, los dominios equivalentes a .com y .edu son .co.uk y .ac.uk("ac" es la abreviatura de "academic"). Está también el dominio .us, organizado geográficamente por estados(por ejemplo, .ny.us se refiere al estado de New York). Ver el RFC 1480 para una descripción detallada del dominio .us.
El mapeado de nombres a direcciones, proceso denominado resolución de nombres de dominio, lo proporcionan sistemas independientes cooperativos, llamados servidores de nombres. Un servidor de nombres es un programa servidor que responde a peticiones de un cliente llamado procesador de nombres.
Cada procesador de nombres está configurado con el nombre del servidor que va a usar(y posiblemente una lista de servidores alternativos con los que contactar si el servidor primario no está disponible). Figura - Resolución de nombres de dominio muestra esquemáticamente cómo un programa utiliza un procesador de nombres para convertir el nombre de un host en una dirección IP. El usuario proporciona el nombre de un host, y al programa de usuario emplea una rutina de librería, llamada stub, para comunicarse con un servidor de nombres que resuelve el nombre del host en una dirección IP y se la devuelve al stub, que a su vez lo devuelve al programa principal. El servidor de nombres pude obtener la respuesta de su caché de nombres, su propia base de datos o cualquier otro servidor de nombres.
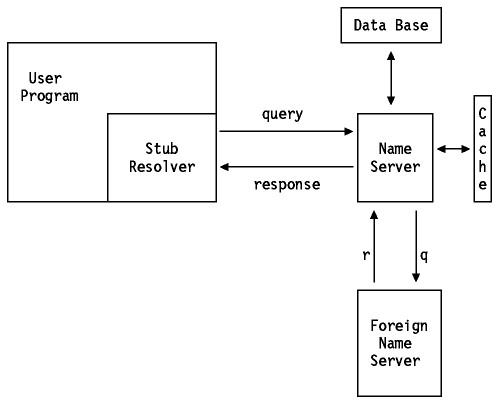
Figura: Resolución de nombres de dominio
El DNS suministra el mapeado de nombres simbólicos a direcciones IP y vice versa. Mientras que en principio es algo sencillo buscar en la base de datos una dirección IP, dado su nombre simbólico, el proceso inverso no se puede hacer respetando la jerarquía. Por este motivo, existe otro espacio de nombres para el mapeado inverso. Se halla en el dominio in-addr.arpa ("arpa" porque Internet era originalmente la red de ARPA). Como las direcciones IP suelen escribirse en formato decimal con puntos, hay una capa de dominios para cada jerarquía. Sin embargo, debido a que los nombres de dominio tienen primero la parte menos significativa del nombre y el formato decimal con puntos los bytes más significativos primero, la dirección decimal se muestra en orden inverso. Por ejemplo, el dominio del DNS correspondiente a la dirección IP 129.34.139.30 es 30.139.34.129.in-addr.arpa. Dada una dirección IP, el DNS puede utilizarse para encontrar el nombre del host que sea su pareja. Una consulta de nombre de dominio para encontrar los nombres del host asociado a una dirección IP se llama "consulta con puntero".
EL DNS está designado para ser capaz de almacenar una gran cantidad de información. Una de las más importantes es información del intercambio de correo, usada para el encaminamiento del correo electrónico. Esto aporta dos servicios: transparencia al reencaminar el correo a un host distinto del especificado y la implementación de pasarelas de correo, que pueden recibir correo electrónico y redirigirlo usando un protocolo diferente de aquel con el que lo reciben. Para más detalles, remitirse a SMTP y el DNS.
Para más detalles sobre la implementación del DNS y el formato de mensajes entre servidores de nombres, ver DNS("Domain Name System"). Los siguientes RFCs definen el estándar de DNS y la información que almacena.
