 Tabla de contenidos
Tabla de contenidos  Arquitectura de encaminamiento NSFNET
Arquitectura de encaminamiento NSFNET
Los IGPs("Interior routing protocols" o "interior gateway protocols") se utilizan para intercambiar información de encaminamiento entre "routers" con un sólo sistema AS("autonomous system"). También lo usan los "routers" que ejecutan protocolos de encaminamiento exterior para recoger información de accesibilidad de la red para el AS.
Los IGPs más usados son:
Antes de discutir en detalle estos tres protocolos, observaremos dos grupos importantes de algoritmo de encaminamiento usados en IGPs.
En esta sección se discuten los algoritmos de encaminamiento Vector-Distancia, Estado del Enlace, y el del Camino Más Corto.
El término Vector-Distancia se refiere a una clase de algoritmos que usan las pasarelas para actualizar su información de encaminamiento. Cada "router" comienza con un conjunto de rutas para aquellas con las que está directamente conectado, y posiblemente algunos "routers" adicionales a otras redes o hosts si la topología de la red es tal que el protocolo de encaminamiento no es capaz de producir el encaminamiento deseado. Esta lista se guarda en una tabla de encaminamiento, en la que cada entrada identifica una red o host de destino y a la "distancia" a ella. Este distancia se denomina métrica y se mide típicamente en saltos.
Periódicamente, cada "router" envía una copia de su tabla de encaminamiento a cualquier otro "router" que pueda alcanzar directamente. Cuando un informe le llega al "router" B del A, B examina el conjunto de destinos que recibe y la distancia a cada uno. B actualizará su tabla de encaminamiento si:
- A conoce un camino más corto a cada destino.
- A lista un destino que B no tiene en su tabla.
- La distancia de A a un destino desde B pasando por A ha cambiado.
Esta clase de algoritmo es fácil de implementar, pero tiene un número de desventajas:
- Cuando las rutas cambian rápidamente, es decir, aparece una nueva conexión o falla una vieja, la topología de encaminamiento puede no estabilizar la topología cambiada debido a que la información se propague lentamente y mientras se esté propagando, algunos "routers" tengan información de encaminamiento incorrecta.
Otra desventaja es que cada "router" tiene que enviar una copia de toda su tabla de encaminamiento a cada vecino a intervalos regulares. Por supuesto, se pueden usar intervalo más largos para reducir la carga de la red pero eso introduce problemas relacionados con la respuesta de la red a cambios en la topología.
Los algoritmos vector-distancia que usan la cuenta de saltos como métrica no tienen en cuenta la velocidad o la fiabilidad del enlace.
La tarea más difícil en uno de estos algoritmos es prevenir la inestabilidad. Existen distintas soluciones:
Elijamos un valor de 16 para representar infinito. Suponer que una red se vuelve inestable; todos sus vecinos generan un timeout y fijan la métrica de esa red a 16. Podemos considerar que todos los "routers" vecinos tienen algún elemento hardware que los conecta con la red desaparecida, con un coste de 16. Ya que se trata de su única conexión con esa red, el resto de los "router" convergerá hacia nuevas rutas que pasen por los vecinos con una conexión directa pero no disponible. Una vez que se ha producido la convergencia, todos los "routers" tendrán una métrica de16 para la red desaparecida. Como 16 indica infinito, la red será inaccesible para todos.
La cuestión con los algoritmos vector-distancia no es si se producirá la convergencia, sino cuánto tiempo llevará. Consieremos la configuración mostrada en Figura - El problema de la cuenta hasta infinito.
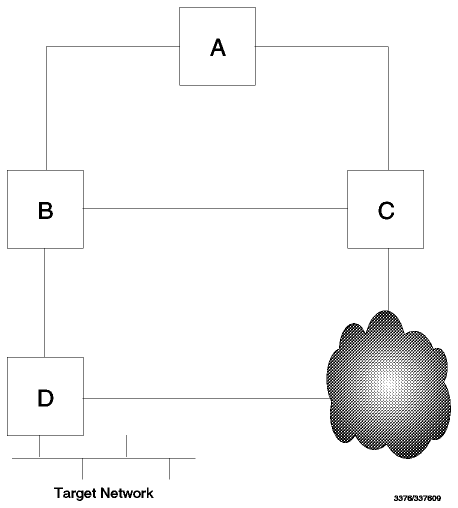
Figura: El problema de la cuenta hasta infinito - Todos los enlaces tienen una métrica de 1 excepto por la ruta indirecta de C a D que tiene métrica de 10.
Considerar ahora sólo las rutas de cada pasarela a la red de destino.
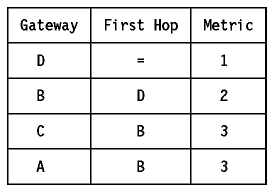
Considerar ahora que el enlace de B a D falla. Las rutas se deberían ajustar para utilizar el enlace de C a D. Los cambios en el encaminamiento comienzan cuando B se da cuenta de que la ruta D ya no es utilizable. En RIP esto sucede cuando B no recibe actualización de su enlace durante 180 segundos.
La siguiente imagen muestra la métrica para la red de destino, como aparece en la tabla de encaminamiento de cada pasarela.
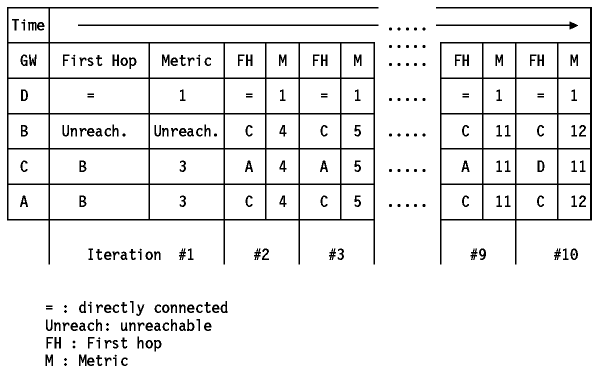
Figura: El problema de la cuenta hasta infinito
El problema es que B se puede liberar de su ruta a (con un mecanismo de timeout), pero quedan vestigios de esa ruta en el sistema durante mucho tiempo(el tiempo entre iteraciones es de 30 segundos en RIP). Inicialmente, A y C todavía piensan que pueden alcanzar a D vía B, así que siguen enviando actualizaciones con métricas de 3. B las recibirá y, en la siguiente iteración, dirá que puede llegar a D por A o por C. Por supuesto, no puede, ya que las rutas dadas por A y C(D alcanzable vía B con métrica 3) ya no están, pero no hay forma de saberlo aún. Incluso cuando descubren que sus rutas por B han desaparecido, todavía piensan que hay una ruta disponible a través del otro. Al final el sistema convergerá, cuando el enlace directo de C a D tenga menor coste que el recibido(por C) de B a A. El peor caso es cuando una red se vuelve completamente inaccesible desde alguna parte del sistema: en este caso, las métricas se pueden incrementar lentamente de modo parecido al indicado arriba hasta que finalmente alcancen el valor infinito. Por esta razón, el problema se llama cuenta hasta infinito. De esta forma, la elección de la "infinidad" es un compromiso entre el tamaño de la red y la velocidad de convergencia en el caso de que la cuenta se produzca. Esto explica por qué se elige una valor tan bajo como16, que es el usado por RIP.
3.3.1.2 Estado del enlace, Primero el Camino Más Corto
El crecimiento de las redes durante los últimos años ha forzado los IGPs más allá de sus límites. La alternativa primaria a los esquemas vector-distancia es una clase de protocolos conocida como Estado del enlace, Primero el Camino Más Corto.
Sus características principales son:
- Un conjunto de redes físicas se divide en un número de áreas.
- Todos los "routers" dentro de un área tiene idénticas bases de datos.
- La base de datos de cada "router" describe la topología completa del dominio de encaminamiento(qué "routers" se conectan a qué redes). La topología de un área se representa en una base de datos denominada LSD("Link State Database") que es una descripción de todos los enlaces de los "routers" del área.
- Cada "router" usa su base de datos para derivar el conjunto de caminos mínimos a todos los destinos de los que construye su tabla. El algoritmo usado para determinar los caminos óptimos se llama SPF("Shortest Path First").
En general, un protocolo enlace estado trabaja del modo siguiente. Cada "router" envía periódicamente una descripción de su conexión(el estado de su enlace) a sus vecinos(aquellos conectados a la misma red). Esta descripción, llamada LSA ("Link State Advertisement"), incluye el coste de la conexión. El LSA inunda el dominio del "router". Cada "router" del dominio mantiene una copia idéntica y sincronizada de una base de datos compuesta de la información del estado del enlace. Esta base de datos describe la topología del dominio como las rutas a redes fuera del dominio como son rutas a redes en otros AS. Cada "router" ejecuta un algoritmo sobre su base de datos resultando en un árbol del camino mínimo(MST o "Minimun Spanning Tree"), que contiene la ruta más corta para cada "router" y red que pueda alcanzar la pasarela. A partir de él, el coste hasta el destino y el salto siguiente para retransmitir un dato se utilizan para construir la tabla de encaminamiento del "router".
Este tipo de protocolos, en comparación con los protocolos vector-distancia, envían actualizaciones cuando hay noticias, que pueden ser regulares para asegurar a los vecinos que la conexión sigue activa. Lo que es más importante, la información intercambiada es el estado del enlace, no los contenidos de la tabla de encaminamiento. Esto significa que los algoritmos del estado del enlace usan menos recursos que su contrapartida vector-distancia, sobre todo cuando el encaminamiento es complejo o el AS grande. Sin embargo, tienen un elevado coste computacional. A cambio, los usuarios consiguen respuesta a los eventos de red más rápido, convergencia más veloz, y acceso a servicios de red más avanzados.
Se usó en el software "Fuzzball" para minicomputadores LSI/11, ampliamente usados en la experimentación en Internet. Se describe en el RFC 891 - Protocolos LAN DCN. No es un est de Internet.
Nota: OSPF (ver OSPF("Open Shortest Path First Protocol") Versión 2) incluye un protocolo muy diferente para negociación entre "routers" llamado también Hello.
La comunicación en el protocolo Hello se hace por mensajes Hello sobre datagramas IP. El número de protocolo de Hello es el 63(reservado para "cualquier red local").
El protocolo Hello es significativo parcialmente debido a su amplia distribución durante la expansión de Internet y parcialmente porque es un ejemplo de algoritmo vector-distancia que no usa cuenta de saltos como RIP(ver RIP("Routing Information Protocol") Versión 1) sino retardos de red como métrica.
Un host físico DCN("Distributed Computer Network") es un procesador compatible con el PDP11 que soporta un número de procesos cooperativos secuenciales, a cada uno de los cuales se le da un id unívoco de 8 bits llamado su ID de puerto. Cada host DCN contiene uno o más procesos de Internet , cada uno de los cuales soporta un host virtual dado un ID de 8 bits, llamado el ID de host. Existe una correspondencia uno a uno entre las direcciones de Internet y los IDs de hosts. Todos los host físicos DCN se identifican por su ID de host con el fin de detectar bucles al actualizar tablas, que establecen los caminos de mínimo retardo entre los host virtuales.
Cada host físico tiene dos tablas:
- Tabla de Host
- Contiene estimaciones del retardo del viaje de ida y vuelta y un desplazamiento lógico de reloj(es decir, la diferencia entre el reloj lógico de este host y el del emisor). Se indexa por el número de host. Se mantiene dinámicamente mediante actualizaciones generadas por mensajes Hello periódicos(de 1 a 30 segundos).
- Tabla de red
- Contiene una entrada para cada red vecina conectable a la red local y a otras redes concretas que no sean vecinas. Cada entrada contiene el número de red, además del número de host del "router"(localizado en la red local) para esa red. Esta tabla se inicializa en tiempo de configuración para todos los host excepto en aquellos que soporten los protocolos de encaminamiento GGP o EGP. En estos casos, se actualiza como parte de la operación de encaminamiento.
Además, las entradas de ambas tablas las pueden cambiar los comandos del operador.
El retardo y el desplazamiento estimados son actualizados por mensajes Hello intercambiados en los enlaces que conectan los vecinos físicos.
Este es el formato de un mensaje Hello:
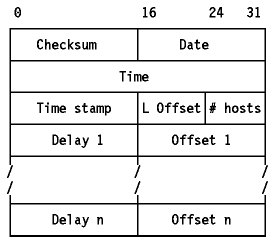
Figura: Formato del mensaje Hello
Donde:
- Checksum
- contiene un checksum cubriendo los campos indicados
- Date
- es la fecha local del host
- Time
- es la hora local del host
- Timestamp
- Usado en cálculos del tiempo de viaje
- L Offset
- contiene el desplazamiento del bloque de entradas de direcciones de Internet usado en la red local
- #hosts
- contiene el número de entradas de la tabla de host siguiente
- Delay n
- Retardo hasta el host n
- Offset n
- offset para el host n (diferencia entre los relojes)
Consideremos ahora los dos pasos principales del protocolo Hello.
Periódicamente cada host envía un mensaje Hello a su vecino en cada enlace común. Para cada uno de estos enlaces el emisor guarda un conjunto de variables de estado, incluyendo una copia de del campo dirección fuente del último mensaje Hello recibido. Al construir un mensaje Hello el emisor fija el campo de destino a su variable de estado y el de dirección fuente su propia dirección. Luego rellena los campo s fecha y hora a partir de su reloj y el sello de tiempo de otra variable de estado. Finalmente copia el retardo y los valores de offset de su tabla de host al mensaje.
Los cálculos del retardo del viaje se realizan cuando el host recibe el mensaje. Cada enlace tiene asignada una variable interna de estado, que se actualiza a la recepción de cada mensaje Hello; esta variable toma el valor del campo hora, menos la hora actual de ese momento. Cuando se transmite el siguiente mensaje Hello, el valor asignado al campo sello de tiempo se computa como los 16 bits de oren inferior de esta variable menos la hora actual. El retardo se calcula como los 16 bits de orden inferior de la hora actual menos el valor del sello de tiempo.
Cuando llega un mensaje Hello, lo que da lugar al cálculo de un retardo de viaje, se efectúa un proceso de actualización del host. Consiste en añadir el retardo a cada una de las n entradas de retardos en el mensaje Hello y en comparar cada uno de esos valores con el campo retardo("delay") de la tabla de host correspondiente. Cada entrada se actualiza según las siguiente reglas:
- Si el enlace conecta con otro host en la misma red y el ID de puerto del proceso de salida del enlace coincide con el campo ID de puerto de la entrada, se actualiza la entrada.
- Si el enlace conecta a otro host en la misma red y el ID de puerto del proceso de salida del enlace no coincide con el número de puerto de la entrada y el retardo calculado es menor que el campo de retardo del host de la tabla de host en al menos un umbral de conmutación especificado(habitualmente 100ms), se actualiza la entrada. Por ejemplo, si el host A envía a B un mensaje Hello, y el retardo actual de B para alcanzar es mayor que el retardo de A a D más el retardo de B a A, B cambia su ruta y envía el tráfico a D por A.
El propósito del umbral de conmutación es evitar(además de ser una especificación del retardo mínimo) conmutaciones innecesarias entre enlaces y bucles transitorios que pueden ocurrir debido a variaciones normales en los retardos de propagación.
Remitirse al RFC 891 para más detalles.
Hay dos versiones de RIP. La versión 1, llamada RIP a secas, es un protocolo muy extendido con un número de limitaciones conocidas. La versión 2 es una versión mejorada diseñada para aliviar estas limitaciones siendo al mismo tiempo muy compatible con su predecesor.
3.3.3.1 RIP("Routing Information Protocol" Versión 1)
RIP es un protocolo est (STD 34). Su status es electivo. Se describe en el RFC 1058, aunque muchas implementaciones de RIP datan de años atrás a este RFC. RIP se implementa con un "demonio" llamado "routed". También soportan RIP los "demonios" de tipo gated.
RIP se basa en los protocolos de encaminamiento PUP y XNS de Xerox PUP. Es muy usado, ya que el código está incorporado en el código de encaminamiento del BSD UNIX que constituye la base para muchas implementaciones de UNIX.
RIP es una implementación directa del encaminamiento vector-distancia para LANs. Utiliza UDP como protocolo de transporte, con el número de puerto 520 como puerto de destino(ver UDP("User Datagram Protocol") para una descripción de UDP y de los puertos). RIP opera en uno de dos modos: activo (normalmente usado por "routers") y pasivo (normalmente usado por hosts). La diferencia entre los dos se explica más abajo. Los mensajes RIP se envían en datagramas UDP y cada uno contiene hasta 25 pares de números como se muestra en Figura - MensajesajeRIP.

Figura: Mensaje RIP - En un mensaje RIP se pueden listar entre 1 y 25 rutas. Con 25 rutas el mensaje tiene 504 bytes(25x20+4) que es el tamaño máximo que se puede transmitir en un datagrama UDP de 512 bytes.
- Command
- es 1 para una petición RIP o 2 para una respuesta.
- Version
- es 1.
- Address Family
- es 2 para direcciones IP.
- IP address
- es la dirección IP de para esta entrada de encaminamiento: un host o una subred(caso en el que el número de host es cero).
- Hop count metric
- es el número de saltos hasta el destino. La cuenta de saltos para una interfaz conectada directamente es de 1, y cada "router" intermedio la incrementa en 1 hasta un máximo de 15, con 16 indicando que no existe ruta hasta el destino.
Tanto el modo activo como el pasivo escuchan todos los mensajes de broadcastadcast y actualizan su tabla de encaminamiento según el algoritmo vector-distancia descrito antes.
- Cuando RIP se inicia envía un mensaje a cada uno de sus vecinos(en el puerto bien conocido 520) pidiendo una copia de la tabla de encaminamiento del vecino. Este mensaje es una solicitud(el campo "command" se pone a 1) con "address family" a 0 y "metric" a 16. Los "routers" vecinos devuelven una copia de sus tablas de encaminamiento.
- Cuando RIP está en modo activo envía toda o parte de su tabla de encaminamiento a todos los vecinos(por broadcastadcast y/o con enlaces punto a punto. Esto se hace cada 30 segundos. La tabla de encaminamiento se envía como respuesta("command" vale 2, aun que no haya habido petición).
- Cuando RIP descubre que una métrica ha cambiado, la difunde por broadcastadcast a los demás "routers".
- Cuando RIP recibe una respuesta, el mensaje se valida y la tabla local se actualiza si es necesario.
Para mejorar el rendimiento y la fiabilidad, RIP especifica que una vez que un "router"(o host) a aprendido una ruta de otro, debe guardarla hasta que conozca una mejor(de coste estrictamente menor). Esto evita que los "routers" oscilen entre dos o más rutas de igual coste.
- Cuando RIP recibe una petición, distinta de la solicitud de su tabla, se devuelve como respuesta la métrica para cada entrada de dicha petición fijada al valor de la tabla local de encaminamiento. Si no existe ruta en la tabla local, se pone a 16.
- Las rutas que RIP aprende de otros "routers" expiran a menos que se vuelvan a difundir en 180 segundos(6 ciclos de broadcastadcast). Cuando una ruta expira, su métrica se pone a infinito, la invalidación de la ruta se difunde a los vecinos, y 60 segundos más tarde, se borra de la tabla.
RIP no está diseñado para resolver cualquier posible problema de encaminamiento. El RFC 1720 (STD 1) describe estas limitaciones técnicas de RIP como "graves" y el IETF está evaluando candidatos para reemplazarlo. Entre los posibles candidatos están OSPF("Open Shortest Path First Protocol" Versión 2) y el IS-IS de OSI IS-IS (ver IS-IS("Intermediate System to Intermediate System" de OSI)). Sin embargo, RIP está muy extendido y es probable que permanezca sin sustituir durante algún tiempo. Tiene las siguientes limitaciones:
- El coste máximo permitido en RIP es 16, que significa que la red es inalcanzable. De esta forma, RIP es inadecuado para redes grandes(es decir, aquellas en las que la cuenta de saltos puede aproximarse perfectamente a 16).
- RIP no soporta máscaras de subred de longitud variable(variable subnetting). En un mensaje RIP no hay ningún modo de especificar una máscara de subred asociada a una dirección IP.
- RIP carece de servicios para garantizar que las actualizaciones proceden de "routers" autorizados. Es un protocolo inseguro.
- RIP sólo usa métricas fijas para comparar rutas alternativas. No es apropiado para situaciones en las que las rutas necesitan elegirse basándose en parámetros de tiempo real tales como el retardo, la fiabilidad o la carga.
- El protocolo depende de la cueanta hasta infinito para resolver algunas situaciones inusuales. Como se describió antes (Vector-Distance), la resolución de un bucle requeriría mucho tiempo(si la frecuencia de actualizaciones fuese limitada) o mucho ancho de banda(si las actualizaciones se enviasen por cada cambio producido). A medida que crece el tamaño del dominio, la inestabilidad del algoritmo vector-distancia de cara al cambio de topología se hace patente. RIP especifica mecanismos para minimizar los problemas con la cuenta hasta infinito(descritos más abajo) que permiten usarlo con dominios mayores, pero eventualmente su operatividad será nula. No existe un límite superior prefijado, pero a nivel práctico este depende de la frecuencia de cambios en la topología, los detalles de la topología de la red, y lo que se considere como un intervalo máximo de tiempo para que la topología de encaminamiento se estabilice.
La resolución de la cuenta hasta infinito se efectúa usando las técnicas split horizon, poisoned reverse y triggered updates.
Consideremos nuestra red de ejemplo(mostrada en Figura - El problema de la cuenta hasta infinito) de nuevo.
Figura: El problema de la cuenta hasta inifinito - Todos los enlaces tienen una métrica de 1 excepto por la ruta indirecta de C a DD que tiene una métrica de 10.
Como se describió en Vector-Distancia, el problema lo causaba el hecho de que A y C se decepcionan mutuamente. Cada uno afirma ser capaz de alcanzar a D a través del otro. Este hecho se puede evitar siendo más cuidadoso con el destino de la información. En particular, nunca es útil afirmar la accesibilidad a una red de destino a través del vecino del que se aprendió la ruta. El método split horizon con poisoned reverse incluye las rutas en las actualizaciones enviadas al "router" el que se aprendieron, pero pone sus métricas a infinito. Si dos "routers" tienen rutas apuntándose recíprocamente, el anunciar las rutas en bucle con métrica de 16 romperá el bucle inmediatamente. Si simplemente no se anuncian estas rutas(esquema conocido como simple split horizon), las rutas erróneas tendrán que ser eliminadas tras un timeout. Poisoned reverse tiene una desventaja: incrementa el tamaño de los mensajes de encaminamiento.
Split horizon con poisoned reverse evita cualquier bucle que implique sólo dos pasarelas. Sin embargo, aún es posible acabar con situaciones en las de este tipo. Por ejemplo, A puede creer que tiene una ruta a través de B, B a través de C, y C a través de A. Esto no se puede solucionar con el método split horizon. Este bucle sólo se arreglará cuando la métrica alcance infinito y la red o el host implicados se declaren inaccesibles. El método triggered updates es un intento de acelerar esta convergencia. Siempre que un "router" cambia la métrica de una ruta, se le requiere que envía mensajes casi inmediatemente, incluso aunque no sea el momento de una actualización(RIP especifica un pequeño intervalo, entre 1 y 5 segundos, con el fin de evitar que estas actualizaciones generen un tráfico de red excesivo).
3.3.3.2 RIP-2("Routing Information Protocol" Versión 2)
RIP-2 es un borrador. Su status es electivo. Se describe en el RFC 1723.
RIP-2 extiende RIP-1. Es menos potente que otros IGPs recientes tales como OSPF(ver OSPF("Open Shortest Path First Protocol") Versión 2) de IS-IS (ver IS-IS("Intermediate System to Intermediate System") de OSI)), pero tiene las ventajas de una fácil implementación y menores factores de carga. La intención de RIP-2 es proporcionar una sustitución directa de RIP que se pueda usar en redes pequeñas y medianas, en presencia de subnetting variable(ver Subredes) o supernetting (ver CIDR("Classless Inter-Domain Routing")) y, sobretodo, que pueda interoperar con RIP-1.
RIP-2 aprovecha que la mitad de los bytes de un mensaje RIP están reservados(deben ser cero) y que la especificación original estaba diseñada con las mejoras en la mente de los desarrolladores, particularmente en el uso del campo de versión. Un área notable en la que este no es el caso es la interpretación del campo de métrica. RIP-1 lo especifica con un valor de 0 a 16 almacenado en un campo de 4 bytes. Por compatibilidad, RIP-2 preserva esta definición, lo que significa en que interpreta 16 como infinito, y desperdicia la mayor parte del rango de este campo.
Nota: Ni RIP-1 ni RIP-2 son adecuados para ser usados como IGPs en un AS en el que el valor de 16 sea demasiado bajo para ser considerado infinito, ya que lo valores altos del infinito exacerban el problema de la cuenta hasta infinito. El protocolo estado del enlace, más sofisticado, usado en OSPF y en IS-IS proporciona una solución de encaminamiento mucho mejor cuando el AS es lo bastante largo para tener una cuenta de saltos cercana a 16.
Si una implementación de RIP obedece la especificación RFC 1058, RIP-2 puede interoperar con ella. El formato del mensaje RIP-2 se muestra en Figura - MensajesajeRIP-2.
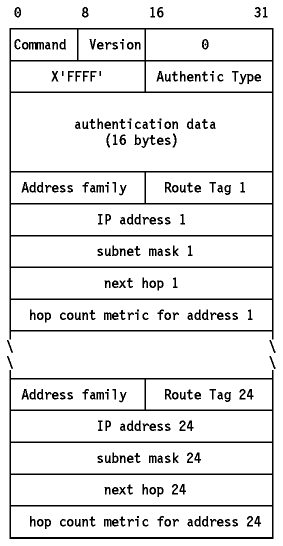
Figure: Mensaje RIP-2 - La primera entrada del mensaje puede ser una entrada de autentificación, como se muestra aquí, o una ruta como en el mensaje RIP. Si la primera entrada es de autentificación, sólo se pueden incluir 24 rutas en el mensaje; de otro modo, el máximo es 25, como en RIP.
Los campos del mensaje RIP-2 son los mismos que en RIP excepto los siguientes:
- Version
- es 2. Le dice al "router" RIP-1 que ignore los campos reservados, los que deben ser cero(si el valor es 1, los "routers" deben desechar los mensaje con valores distintos de cero en estos campos, ya que los originó un "router" que dice ser RIP, pero que envía mensajes que no cumplen el protocolo).
- Address Family
- puede ser X'FFFF' sólo en la primera entrada, indicando que se trata de una entrada de autentificación.
- Authentication Type
- Define como se han de usar los restantes 16 bytes. Los únicos tipos definidos son 0, indicando ninguna autentificación, y 2 indicando que el campo contiene datos de password.
- Authentication Data
- el password es de 16 bytes, texto ASCII plano, alineado a la izquierda y rellenado con caracteres nulos ASCII (X'00').
- Route Tag
- es un campo dirigido a la comunicación de información acerca del origen de la información de encaminamiento. Está diseñado para la interoperabilidad entre RIP y otros protocolos de encaminamiento. Las implementaciones de RIP-2 deben conservarlo, aunque RIP-2 no especifica como se debe usar.
- Subnet Mask
- la máscara de subred asociada con la subred a la que se refiere esta entrada.
- Next Hop
- Una recomendación acerca del siguiente salto que el "router" debería usar para enviar datagramas a la subred o al host dado en la entrada.
Para asegurar una interoperabilidad segura con RIP, el RFC 1723 especifica las siguientes restricciones para los "routers" RIP-2 que transmiten sobre una interfaz de red en la que un "router" RIP puede escuchar y operar con mensajes RIP.
- La información interna a una red nunca se debe anunciar a otra red.
- La información acerca de una subred más específica no se debe anunciar donde los "routers" vean una ruta de host.
- Las rutas a superredes(rutas con una máscara de subred más corta que la máscara natural de la red) no se deben anunciar en los sitios en los que puedan ser malentendidas por los "routers" RIP.
RIP-2 soporta además el multicast con preferencia al broadcastadcast. Esto puede reducir la carga de los host que no están a la escucha de mensajes RIP-2. Esta opción es configurable para cada interfaz para asegurar un uso óptimo de los servicios RIP-2 cuando un "router" conecta redes mixtas RIP-1/RIP-2 con redes RIP-2. Similarmente, el uso de la autentificación en entornos mixtos se puede configurar para adecuarse a los requerimientos locales.
RIP-2 está implementado en versiones recientes del "gated daemon", llamado con frecuencia "gated Version 3". Ya que el borraddor es nuevo en el momento de su redacción, muchas implementaciones se ajustarán a la versión anterior descrita en el RFC 1388. Tales implementaciones interoperarán con aquellas que se adhieran al RFC 1723.
Para más información acerca de RIP-2, ver:
- RFC 1721 - Análisis
del protocolo RIP Versión 2
- RFC 1722 - Aplicabilidad del protocolo RIP Versión 2
- RFC 1723 - RIP Versión 2 - Transmisión de información adiciona
- lRFC 1724 - Extensión MIB de RIP Versión 2
Nota: El término OSPF se usa invariablemente para referirse a OSPF Versión 2 (OSPF-2). OSPF Version 1, descrito en el RFC 1131, es obsoleto.
OSPF es un borrador. Su status es electivo, pero el RFC 1370 contiene condiciones de aplicabilidad para OSPF que dicen que cualquier "router" que implemente un protocolo distinto del encaminamiento IP simple debe implementar OSPF(lo que no significa que el "router" pueda implementar otros protocolos, por supuesto). OSPF se describe en el RFC 1583, que desfasa al RFC 1247. Las implementaciones basadas en el RFC 1583 son retrocompatibles con las basadas en el 1247 y pueden interoperar con ellas. Los apéndices F del RFC 1247 y E del 1583 hablan del desarrollo de OSPF 2 a partir de OSPF 1.
OSPF es un protocolo de encaminamiento interior, pero está diseñado para operar con un protocolo exterior adecuado, tal como BGP. Ver Interacción BGP OSPF.
OSPF es un est complejo en comparación con RIP: el RFC 1583 tiene 216 páginas, mientras que RIP, especificado en el RFC 1058 tiene 33 y RIP-2 (RFC 1723) 9 más. Mucha de su complejidad tiene un sólo propósito: asegurar que las bases de datos topológicas son las mismas para todos los "routers" dentro de un área. Debido a que la base de datos es la base para todas las decisiones de encaminamiento, si los "routers" tuvieran bases de datos independientes, podrían tomar decisiones mutuamente conflictivas.
OSPF se comunica por medio de IP(su número de protocolo es el 89). Es un protocolo de estado del enlace, primero el camino más corto, como se describe en Estado del enlace, primero el camino más corto. OSPF soporta distintas clases de redes tales como redes punto a punto, de broadcastadcast, como Ethernet y redes en anillo, y de no broadcastadcast, como X.25.
La especificación de OSPF hace uso de máquinas de estado para definir el comportamiento de los "routers" que siguen el protocolo. Cada aspecto del trabajo de un "router" importante para OSPF, como sus interfaces de red y sus vecinos, puede hallarse en uno de un número finito de estados(por ejemplo, un vecino puede estar en el estado "caído"). Hay una máquina para componente(por ejemplo, dos interfaces de red tiene diferentes máquinas) y el estado de uno es independiente del resto. Los estados posibles bastan para describir todas las posibles condiciones relevantes al protocolo, por lo que una máquina de estados está siempre en uno, y sólo uno, de sus posibles estados. Los cambios de estado se producen como resultado de eventos. Hay un conjunto finito de eventos para cada tipo de máquina que es suficiente para representar todas las posibles ocurrencias del protocolo. El comportamiento de una máquina en respuesta a un evento viene dado por todas las posibles combinaciones de estado y evento. Por ejemplo, si la máquina de estado para una interfaz de red experimenta un evento InterfaceDown (CaídaDeInterfaz), la máquina cambia incondicionalmente al estado down(caído). El evento InterfaceDown lo genera la implementación de OSPF cuando recibe una indicación de un protocolo de nivel inferior de que la interfaz no está operativa. Ver el RFC 1583 para un descripción completa de cada máquina, sus posibles estados y eventos y los cambios asociados a ellos.
Aquí hay algunas definiciones necesarias para entender la secuencia de operaciones descrita posteriormente en esta sección:
- Area
- Conjunto de redes dentro de un sólo AS que se han agrupado juntas. La topología de un área permanece oculta al resto del AS, y cada área tiene una base de datos topológica separada. El encaminamiento en el AS se produce en dos niveles, dependiendo de si la fuente y el destino de un paquete están en la misma área(intra-area routing) o en áreas diferentes(inter-area routing).
- El encaminamiento intra-area lo determina sólo la propia topología del área. Es decir, el paquete se encamina sólo a partir de información obtenida dentro del área; no se puede usar información de encaminamiento obtenida fuera de la misma.
- El encaminamiento inter-area se hace siempre a través de la troncal.
- La división de un sistema autónomo en áreas permite una reducción significante en el volumen del tráfico de encaminamiento requerido para gestionar la base de datos en un AS grande.
- Backbone
- El backbone o troncal consiste en aquellas redes no contenidas en ningún área, los "routers" conectados a estas, y los "routers" pertenecientes a múltiples áreas. La troncal debe ser contigua a nivel lógico. Si no es contigua físicamente, los componentes deben usar enlaces virtuales(ver más bajo). La troncal es responsable de la información de encaminamiento entre áreas. La troncal misma tiene las propiedades de un área; su topología está separada de las de otras áreas.
- Area Border Router(ABR)
- Un "router" conectado a múltiples áreas. Tiene una copia de la base de datos de cada área a la que está conectado. Siempre forma parte de la troncal, y son responsables de la propagación de la información de encaminamiento inter-area a las áreas a las que están conectados.
- Internal Router(IR)
- Un "router" que no es de tipo ABR.
- AS Border Router(ASBR)
- Un "router" que intercambia información de encaminamiento con "routers" pertenecientes a otros AS. Todos los "routers" de un AS conocen el camino al todos los "routers" de tipo "boundary". Un ASBR puede ser un ABR o un IR. No tiene que ser parte de la troncal.
- Nota:
La nomenclatura para este tipo de "router" varía. El RFC 1583, usa el término AS Boundary Router. Los RFCs 1267 y 1268, Border Router y Border Gateway. El RFC 1340, AS Border Router. En adelante, usaremos este último.
- Virtual Link (VL)
- Un VL o enlace virtual es parte de la troncal. Sus extremos son dos ABR que comparten un área no troncal. El VL se trata como un enlace punto a punto con métrica igual a la métrica intra-area entre los extremos. El encaminamiento a través del VL se hace usando encaminamiento intra-area normal.
- Transit Area
- Un área a través de la que se produce la conexión física de un VL.
- Stub Area(SA)
- Un área configurada para usar el encaminamiento por defecto para el encaminamiento inter-AS. Se puede configurar en los sitios donde hay un sólo punto de salida del área, o donde se puede usar cualquier salida sin preferencia por ninguna ruta. Por defecto, las rutas inter-AS se copian a todas las áreas, por lo que el uso de SAs puede reducir las necesidades de almacenamiento de los "routers" dentro de aquellas áreas donde hay definidas muchas rutas inter-AS.
- Multiaccess Network
- Una red física que soporta la conexión de múltiples "routers". Se asume que cada par de "routers" de tal red es capaz de comunicarse directamente.
- Hello Protocol
- La parte del protocolo OSPF usada para establecer un mantener relaciones vecinales. No es el protocolo Hello descrito en El protocolo Hello.
- Neighboring routers
- Dos "routers" que tienen interfaces a una red común. En redes multiacceso, los vecinos se descubren dinámicamente por medio del protocolo Hello.
- Cada vecino se representa con una máquina de estado que describe la conversación entre este "router" y su vecino. A continuación se muestra un breve boceto del significado de los estados. Ver la sección siguiente para una definición de los términos adyacencia y "router" designado.
- Down
- Estado inicial de la conversación de un vecino. Indica que no ha habido información reciente recibida del vecino.
- Attempt
- Un vecino o una red no broadcastadcast parece estar en estado "down" y se debería intentar contactar con ella enviando paquetes Hello regulares.
- Init
- Se ha recibido recientemente u paquete Hello del vecino. Sin embargo, la comunicación bidireccional no se ha establecido aún con él(es decir, el propio "router" no aparece en el paquete Hello).
- 2-way
- En este estado, la comunicación entre dos "routers" es bidireccional. Se pueden establecer adyacencias, y los vecinos en este estado o en uno superior se pueden elegir como "routers" designados(de backup o copia de seguridad).
- ExStart
- Los dos vecinos están a punto de crear una adyacencia.
- Exchange
- Los dos vecinos se dicen el uno al otro lo que tienen en sus bases de datos topológicas.
- Loading
- Los dos vecinos están sincronizaciónronizando sus bases de datos topológicas.
- Full
- Los dos vecinos son ahora totalmente adyacentes, y sus bases de datos están sincronizadas.
Varios eventos causan un cambio de estado. Por ejemplo, si un "router" recibe un paquete de un vecino en estado "down", el estado del vecino cambia a "init", y se inicia un contador de inactividad. Si el contador se dispara(es decir, no se reciben más paquetes OSPF antes de que expire) el vecino retorna al estado "down". Remitirse al RFC 1583 para una desscripción completa de los estados y de la información de los eventos que causan los cambios.
- Adjacency(Adyacencia)
- Una nueva relación formada entre vecinos seleccionados con el fin de intercambiar información de encaminamiento. No todos los pares de vecinos se vuelven adyacentes. En particular, no todos estos pares permanecen sincronizados. Si todos los vecinos tuvieran que estar sincronizados, el número de pares sincronizados en una red multiacceso tal como una LAN sería n(n-1)/2 donde n es el número de "routers" de la LAN. En redes grandes, el tráfico de sincronización inundaría la red, volviéndola inutilizable. El concepto de adyacencias se usa para limitar el número de pares sincronizados a 2n - 1, asegurando que el flujo de sincronización es manejable.
- Link State Advertisement (LSA)
- Se refiere al estado local del "router" o de la red. Esto incluye el estado de las interfaces y adyacencias del "router". El conjunto de LSAs de todos los "routers" y redes forma la base de datos topológica del área.
- Flooding
- El proceso de asegurar que cada LSA se pasa entre "routers" adyacentes para alcanzar a cada "router" del área. Es un procedimiento fiable.
- Designated Router
- Cada red multiacceso con al menos dos "routers" conectados, tiene un DR("Designated Router" o "router" designado). El DR genera un LSA para la red. Ya que todas las bases de datos de todos los "routers" están sincronizadas por medio de las adyacencias, el DR juega un papel central en el proceso de sincronización.
- Backup Designated Router (BDR)
- Con el fin de suavizar la transición a un nuevo DR, existe un BDR para toda red multiacceso. El BDR es además adyacente a todos los "routers" de la red, y se convierte en DR cuando el DR anterior falla. Debido a que ya hay adyacencias entre el BDR y el resto de los "routers", no hace falta crear nuevas cuando el BDR sustituye al DDR, acortando el tiempo de reemplazo considerablemente. El BDR se elige mediante el protocolo Hello.
- Interface
- La conexión entre un "router" una de sus redes. Cada interfaz tiene uno de estado asociada con él que se obtiene de los protocolos de nivel inferior y del mismo OSPF. Aquí se da una breve descripción de cada estado. Remitirse al RFC 1583 para más detalles, y para información sobre los eventos que causan el cambio de los estados.
- Down
- La interfaz no está disponible. Es el estado inicial de la interfaz.
- Loopback
- La interfaz realiza un loop back al "router". No se puede usar para el tráfico regular de datos.
- Waiting
- El "router" está intentando determinar la identidad del DR o del BDR.
- Point-to-Point
- La interfaz se conecta a una red punto a punto o es un VL. El "router" forma una adyacencia con el "router" en el otro extremo.
- Nota:
Las interfaces no necesitan direcciones IP. Como el resto de Internet prácticamente no tiene necesidad de ver las interfaces del "router" en el enlace punto a punto, sólo las interfaces con las otras redes, cualquier dirección IP para el enlace se requeriría sólo para la comunicación entre los dos "routers". Para ahorrar espacio de direcciones IP, los "routers" pueden pasarse sin direcciones IP en el enlace. Esto tiene el efecto de que los dos "routers" parezcan uno sólo, aunque esto no trae inconvenientes. Tal enlace se llama enlace innumerado.
- DR Other
- La interfaz está en una red multiacceso pero el "router" no es el DR ni el BDR. El "router" forma adyacencias con el DR y el BDR.
- Backup
- El "router" es el BDR. Se le ascenderá a DR si el DR actual falla. El "router" forma adyacencias con cualquier otro "router" de la red.
- DR
- El "router" es el DR. Forma adyacencias con todos los demás "routers" de la red. Además debe originar un anuncia del enlace de red para el nodo.
- Type of Service (TOS) metrics
- En cada tipo de anuncio de estado del enlace, se pueden anunciar distintas métricas para cada tipo de servicio IP("IP Type of Service"). Siempre se debe especificar una métrica para TOS 0(usada para el encaminamiento OSPF de paquetes de protocolo). Pueden definirse métricas para otros valores de TOS; si no se hace, se les supone iguales a los de TOS 0.
- Link State Database
- También llamados grafo dirigido o base de datos topológica. Se crea a partir de los anuncios del estado del enlace que generan los "routers" del área.
- Nota:
el RFC 1583 usa el término LSD("Link State Database") con preferencia al de base de datos topológica. En esta sección se ha usado el segundo término, pero en lo que resta de ella, la llamaremos LSD.
- Shortest-Path Tree
- Cada "router" ejecuta el algoritmo SPF("Shortest Path First") en el LSD para obtener su árbol mínimo. El árbol da la ruta a cualquier host o red de destino dentro del área. Se usa para construir la tabla de encaminamiento.
- Nota:
debido a que cada "router" ocupa un lugar diferente en la topología del área, la aplicación del algoritmo SPF da un árbol distinto para cada "router", aunque la base de datos sea idéntica.
- Los ABR pueden ejecutar múltiples copias del algoritmo pero construyen una sola tabla de encaminamiento.
- Routing table
- La tabla de encaminamiento contiene entradas para cada destino: red, subred o host. Para cada destino, hay información para uno o más tipos de servicios(TOS). Para cada combinación de destino y tipo de servicio, hay entradas de una o más rutas óptimas a emplear.
- Area ID(AID)
- Un número de 32 bits que identifica un área particular. La troncal tiene un AID de cero.
- Router ID(RID)
- Un número de 32 bits que identifica un "router" particular. Cada "router" dentro de una AS tiene un RID unívoco. Una posible implementación es usar como RID la menor dirección IP del "router".
- Router Priority(RP)
- Un entero sin signo de 8 bits, configurable por medio de una interfaz que indica la selección del BDR. Un RP de cero indica que el "router" no se puede elegir como DR.
La secuencia básica de operaciones realizadas por los "routers" OSPF routers es:
- Descubrir vecinos OSPF
- Elegir el DR
- Formar adyacencias
- Sincronizar bases de datos
- Calcular la tabla de encaminamiento
- Anunciar los estados de los enlaces
Los "routers" efectuarán todos estos pasos durante su activación, y los repetirán en respuesta a eventos de red. Cada "router" debe ejecutar estos pasos para cada red a la que está conectado, excepto para calcular la tabla de encaminamiento. Cada "router" genera y mantiene una sola tabla de encaminamiento para todas las redes.
Las siguiente secciones describen estos pasos.
Cuando los "routers" OSPF se activan, inician y mantienen relaciones con sus vecinos usando el protocolo Hello. El protocolo además asegura que la comunicación entre vecinos sea bidireccional. Los paquetes Hello se envían periódicamente al exterior por todas las interfaces de los "routers". La comunicación bidireccional se indica si el propio "router" aparece en el paquete Hello del vecino. En una red de broadcast, los paquetes Hello se envían por multicast; los vecinos se descubren luego dinámicamente. En redes no broadcast, cada "router" que sea un DR potencial tiene una lista de todos los "routers" conectados a la red y enviará paquetes Hello a todos los demás DRs potenciales cuando su interfaz a la red sea operativa por primera vez.
La cabecera OSPF se describe en Figura - Cabecera del paquete OSPF.
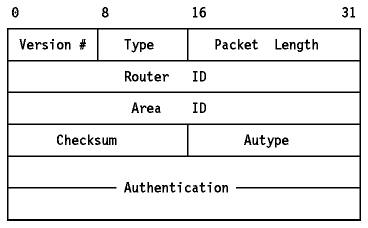
Figura: Cabecera del paquete OSPF
- Version #
- El número de versión de OSPF (2).
- Type
- El tipo: Hello (1), descripción de la base de datos (2), Link-State Request (3), Link-State Update (4), o Link-State Acknowledgment (5).
- Packet length
- Longitud del paquete en bytes incluyendo la cabecera OSPF.
- Router ID
- El ID del "router" que originó el paquete.
- Area ID
- El área a la que se está enviando el paquete.
- Checksum
- El checksum IP est de todo el contenido del paquete, excluyendo el campo de autentificación de 64 bits.
- AuType
- Identifica el esquema de autentificación a usar con el paquete. El tipo de autentificación es configurable en por áreas. Los tipos de autentificación definidos actualmente son: 0 (ninguna autentificación) y 1 (password de 64 bits en texto plano).
- Authentication
- Un campo de 64 bits usado para la autentificación.
El formato del paquete Hello de OSPF Hello se explica en Figura - El paquete Hello de OSPF.
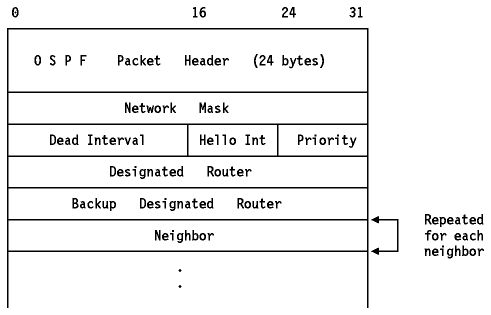
Figura: El paquete Hello de OSPF
- Network Mask
- La máscara de red asociada a la interfaz. Se trata de la máscara de subred, si está implementada, o de su equivalente en una red sin subredes(por ejemplo, 255.255.255.0 para una red clase C si subredes).
- Dead Interval
- El número de segundos que deben pasar antes de hacer que un vecino que permanece en silencio pase al estado "down".
- Hello Int (Hello Interval)
- El número de segundos entre los paquetes Hello enviados por este "router".
- Priority
- La RP("Router Priority") de este "router"(para esta interfaz).
- Designated Router
- La dirección IP del DR de esta red, según el "router" emisor. Se pone a cero si no se conoce ningún DR.
- Backup Designated Router
- La dirección IP del BDR de esta red, según el "router" emisor. Se pone a cero si no se conoce ningún BDR.
- Neighbor
- El RID de cada "router" el que se han recibido paquetes Hello válidos recientemente. Recientemente significa dentro del último DI(Dead Interval).
Esto se hace usando el protocolo Hello. Aquí se da una breve descripción del proceso. Ver el RFC 1583 para una descripción completa. El "router" examina la lista de sus vecinos, desecha cualquiera que no tenga comunicación bidireccional o que tenga un RP de ver, y graba el DR, el BDR y la RP que ha declarado cada uno de ellos. El "router" se añade él mismo a la lista, usando el valor RP configurado para la interfaz y cero(desconocido) para el DR y el BDR, en el caso de que esté en proceso de activación.
Se emplean las siguiente reglas para determinar el BDR:
- Si uno o más "routers" declaran ser el BDR y no el DR, gana el que tenga un RP superior.
- En caso de empate, gana el que tenga mayor RID.
- Si ningún "router" declara ser el BDR, entonces el se elige el "router" con mayor RP a menos que se haya declarado como DR.
- De nuevo, en caso de empate gana el "router" con mayor RID.
Como el propio "router" que hace los cálculos está en la lista, puede determinar que él mismo es el BDR. Un proceso similar se sigue para el DR:
- Si uno o más "routers" declaran ser el DR, gana el que tenga un RP superior.
- En caso de empate, gana el que tenga mayor RID.
- Si ningún "router" ha declarado ser el DR entonces el BDR se convierte en el DR.
El proceso real es mucho más complejo, debido a que los mensajes Hello transmitidos incluyen los cambios en los campos grabados en otros "routers", y estos cambios causan eventos en los "routers" que a su vez podrán provocar nuevos cambio u otras acciones. La intención que se esconde tras este mecanismo es doble:
- Que cuando un "router" se active, no debería usurpar la posición del BDR actual aunque tenga un RP superior.
- Que la promoción de un BDR a DR debería ser ordenada y requerir que el BDR acepte sus responsabilidades.
El algoritmo no siempre da lugar a que el "router" de mayor prioridad sea el DR, ni tampoco que el segundo de mayor prioridad sea el BDR.
El DR tiene las siguiente responsabilidades:
- El DR genera para la red los anuncios de los estados de los enlaces, que inundan el área y describen esta red a todos los "routers" de todas las redes del área.
- El DR se hace adyacente a otros "routers" de la red. Estas adyacencias son centrales con respecto al proceso de inundación usado para asegurar que los anuncios alcanzan a todos los "routers" del área y que por tanto la base de datos topológica que usan todos permanece igual.
El BDR tiene la siguiente responsabilidad:
- El BDR se hace adyacente a todos los demás "routers" de la red. Esto asegura que cuando ocupe el puesto del DR lo pueda hacer rápidamente.
Después de que se ha descubierto un vecino, asegurado la comunicación bidireccional, y(en una red multiacceso) elegido un DR, se toma la decisión de si se debería formar una adyacencia con uno de sus vecinos:
- En redes multiacceso, todos los "routers" se hacen adyacentes al DR y al BDR.
- En enlaces punto a punto(virtuales), cada "router" forma siempre una adyacencia con el "router" del otro extremo.
Si se toma la decisión de no formar una adyacencia, el estado de la comunicación con el vecino permanece en el estado "2-way".
Las adyacencias se establecen usando paquetes DD("Database Description"), que contienen un resumen de la base de datos de estados de enlaces del emisor. Se pueden usar múltiples paquetes para describir la base de datos: con este fin se emplea un procedimiento de sondeo-respuesta. El "router" con mayor ID se convertirá en maestro, el otro en esclavo. Los paquetes DD enviados por el maestro(sondeos o polls) serán reconocidos por los DDs del esclavo(respuestas). El paquete contiene números de secuencia para asegurar la correspondencia entre sondeos y respuestas. Este proceso se denomina DEP("Database Exchange Process").
El formato del paquete DD se muestra en Figura - Paquete DD de OSPF.
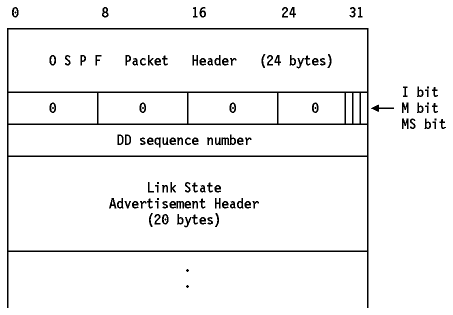
Figura: Paquete DD de OSPF
- 0
- Reservado, debe ser 0.
- I bit
- Bit "Init" o de inicio. Puesto a 1 cuando el paquete es el primero de la secuencia.
- M bit
- Bit "More". Indica que siguen más paquetes DD.
- MS bit
- Bit maestro/esclavo("Master/slave"). Puesto a 1 cuando el "router" es el maestro, a 0 cuando es el esclavo.
- DD sequence number
- Usado para secuenciar la serie de paquetes DD.
El resto del paquete contiene una lista de algunos o todos los contenidos de la base de datos topológica. Cada item de la base de datos es un anuncio de estado del enlace. Los paquetes DD contienen las cabeceras de estos anuncios, que son suficientes para identificar cada anuncio. Esta información se usa en la posterior sincronización de la base de datos. El formato de esta cabecera se muestra en Figura - Cabecera del anuncio del estado del enlace de OSPF.
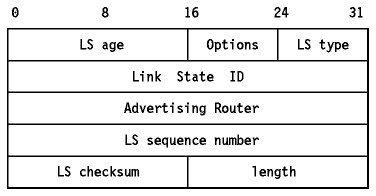
Figura: Cabecera del anuncio del estado del enlace de OSPF
Los campos de la cabecera son:
- LS age
- Un número de 16 bits que indica el tiempo en segundos desde el origen del anuncio. En cada salto viaja como parte del procedimiento de inundación. Cuando alcanza su valor máximo, deja de ser usado para determinar las tablas de encaminamiento y se desecha hasta que se necesite para la sincronización de la base de datos. También se emplea para determinar cuál de dos copias idénticas de un anuncio debería usar un "router".
- Options
- Dos bits que describen capacidades opcionales de OSPF. El bit E indica un servicio de encaminamiento externo; se pone a 1 a menos que el anuncio sea para un "router", enlaces de red o un SL("summary link") en un SA("stub area"). El bit E describe rutas para tipos de servicio en adición a TOS 0.
- LS type
- Los tipos de anuncio de estado del enlace son:
- 1
- RL("Router links"). Describen el estado de las interfaces del "router".
- 2
- NL("Network links"). Describen los "routers" conectados a la red.
- 3
- SL("Summary links"). Describen "routers" inter-area, intra-AS. Los crean los ABR y permiten que las rutas a redes dentro del AS pero fuera del área sean descritas con precisión.
- 4
- $$$SL("Summary links"). Describen rutas a la frontera del AS(es decir, a "routers" fronterizos del AS). Los crean los BR. Son muy similares a los de tipo 3.
- 5
- ASEL("AS external links"). Describen rutas a redes fuera del AS. Los crean los ASBR. Es posible describir una ruta por defecto para el AS de esta forma.
- LSD("Link State ID")
- Un ID único para el anuncio que es dependiente de su tipo. Para los tipos 1 y 4es el RID, para los 3 y 5 es un número IP de red, y para el tipo 2 es la dirección IP del DR.
- AR("Advertising Router")
- El RID del "router" que originó el anuncio. Para el tipo 1, este campo es idéntico al LSD. Para el 2, es el RID del DR. Para los tipos 3 y 4 es el RID de un ABR. Para el 5, es el RID de un ASBR.
- LSN("LS sequence number")
- Usado para permitir la detección de anuncios viejos o duplicados.
- LS checksum
- Checksum de todo el anuncio menos el campo LSA("LS age").
Después de que terminar el DEP("Database Exchange Process"), cada "router" tiene una lista de aquellos anuncios para los que el vecino tiene más instancias actualizadas, que se solicitan por medio de paquetes LSR("Link State Request"). La respuesta a un LSR es un LSU("Link State Update") que contiene algunos o todos los anuncios solicitados. Si no se recibe respuesta, se repite la solicitud.
Los anuncios vienen en cinco formatos el formato de un RLA("Router Links Advertisement"; tipo 1) se muestra en Figura - RLA de OSPF.
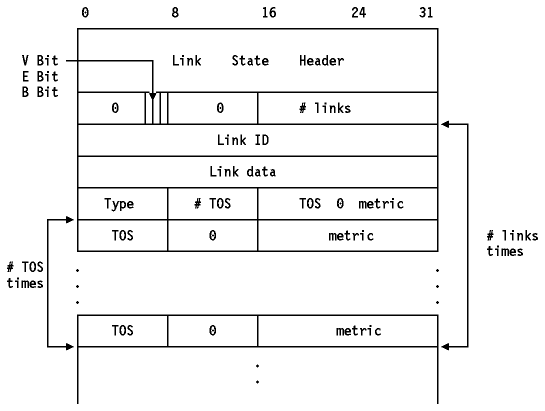
Figura: RLA de OSPF - Este anuncio va encapsulado en un paquete OSPF.
- V Bit
- Cuando está a uno, el "router" es el extremo del enlace virtual que usa este área como área de tránsito.
- E Bit
- Cuando está a uno, el "router" es un ASBR.
- B Bit
- Cuando está a uno, el "router" es un ABR.
- # links
- El número de enlaces que describe el anuncio.
- Link ID
- Identifica el objeto al que conecta este enlace. El valor depende del campo "type"(ver abajo).
- 1
- RID del vecino
- 2
- Dir IP del DR
- 3
- Este valor depende de la ruta inter-area:
- Para una SN("stub network") es el número IP de red/subred
- Para un host, es X'FFFFFFFF'
- Para la ruta externa por defecto el AS es X'00000000'
- 4
- RIDD del vecino
- Link Data
- Este valor también depende del campo "type"(ver el RFC 1583 para más detalles).
- Type
- A qué conecta el enlace.
- 1
- Conexión punto a punto con otro "router"
- 2
- Conexión con una red de tránsito
- 3
- Conexión a una SN o a un host
- 4
- Virtual link
- # metric
- El número de diferentes métricas de TOS para este enlace además de la métrica para TOS 0.
- TOS 0 metric
- El coste de usar el enlace para TOS 0. Todos los paquetes de encaminamiento de OSPF se envían con el campo IP TOS a cero.
- TOS
- Tipo IP de servicio al que se refiere la métrica. El RFC 1349 define los posibles valores TOS en una cabecera IP(ver IP("Internet Protocol")) con una secuencia de 4 bits. OSPF codifica estos códigos tratando la secuencia como un número y duplicándolo(a continuación del campo TOS hay un bit reservado puesto a cero, que OSPF guarda para su posible inclusión en el futuro en el valor TOS. Hay cinco valores definidos:

Tabla: Valores de "Type of Service"
- El coste de usar este "router" para el tráfico del tipo de servicio especificado por el campo "Type of Service".
- Como ejemplo, suponer el enlace punto a punto entre los "routers" RT1 (dirección IP: 192.1.2.3) y RT6 (dirección IP: 6.5.4.3) es como un enlace satélite. Para favorecer el uso de esta línea para el tráfico banda alta, el administrador AS puede fijar artificialmente una métrica baja para ese TOS. RT1 originaría los siguientes anuncios de estado del enlaces(suponiendo que RT1 es un ABR y no un ASBR):
; RT1's router links advertisement
LS age = 0 ; always true on origination
LS type = 1 ; indicates router links
Link State ID = 192.1.2.3 ; RT1's Router ID
Advertising Router = 192.1.2.3 ; RT1
bit E = 0 ; not an AS boundary router
bit B = 1 ; area border router
#links = 1
Link ID = 6.5.4.3 ; neighbor router's Router ID
Link Data = 0.0.0.0 ; interface to unnumbered SL
Type = 1 ; connects to router
# other metrics = 1
TOS 0 metric = 8
TOS = 2 ; high bandwidth
metric = 1 ; traffic preferred
El formato de un NLA("Network Links Advertisement"; tipo 2) se muestra en Figura - NLA de OSPF.
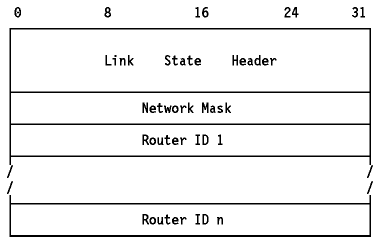
Figura: NLA de OSPF - Este anuncio va encapsulado en un paquete OSPF.
- Network Mask
- La máscara IP para la red. Por ejemplo, una red de clase C tendría una máscara de 255.0.0.0.
- Router ID 1-n
- Las direcciones IP de todos los "routers" de la red que sean adyacentes al DR (incluyendo al "router" emisor). El número de "routers" en una lista se deduce del campo "lenght" de la cabecera.
El formato un SLA("Summary Links Advertisement"; tipo 3 o 4) se muestra en Figura - SLA de OSPF.
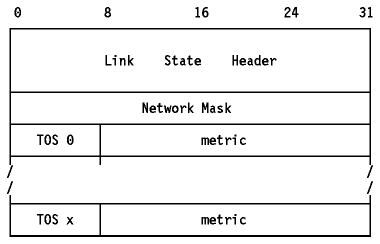
Figura: SLA de OSPF - Este anuncio va encapsulado en un paquete OSPF.
- Network Mask
- Para un anuncio de tipo 3, es la máscara IP para la red. Para uno de tipo 4 no tiene significado y debe ser cero.
- TOS 0
- zero
- metric
- El coste de esta ruta para este tipo de servicio en las mismas unidades usadas para las métricas TOS en los anuncios tipo 1.
- TOS x
- Cero o más entradas para tipos adicionales de servicio. El número de entradas se puede determinar a partir del campo "length" de la cabecera.
El formato de una ELA("External Links Advertisement") se muestra en Figura - ELA de OSPF.
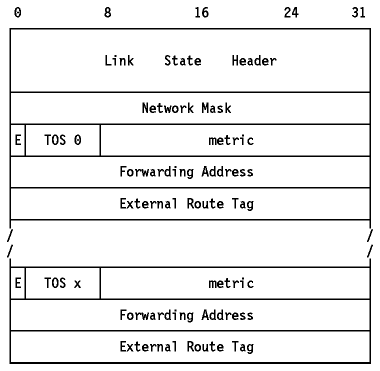
Figura: ELA de OSPF - Este anuncio va encapsulado en un paquete OSPF.
- Network Mask
- La máscara IP para la red.
- Bit E
- El tipo de métrica externa. Si está a uno es 2, sin no es1.
- 1
- La métrica se puede comparar directamente con las métricas del estado del enlace de OSPF
- 2
- La métrica se considera mayor que todas las métricas del estado del enlace de OSPF
- TOS 0
- zero
- metric
- El coste de esta ruta. La interpretación depende del E-bit.
- Forwarding Address
- La dirección IP a la que se ha de dirigir el tráfico de datos del tipo de servicio especificado para ese destino. El valor cero indica que el tráfico se debería enviar al ASBR que originó el anuncio.
- External Route Tag
- Un valor de 32 bits conectado a la ruta externa por un ASBR. OSPF no define o usa este valor, pero Interacción de BGP con OSPF define su uso cuando se emplea BGP como protocolo de encaminamiento externo.
- TOS x
- Cero o más entradas para tipos adicionales de servicio. El número de entrada se puede determinar a partir de la longitud del campo "length" de la cabecera.
Cuando se han respondido los paquetes LSR, las bases de datos se sincronizan y los "routers" se describen como totalmente adyacentes. La adyacencia se añade a los anuncios de los dos "routers" correspondientes.
Usando como entrada las bases de datos de estados de enlaces de las áreas con las que está conectado, un "router" ejecuta el algoritmo SPF para construir su tabla de encaminamiento. La tabla de encaminamiento siempre se construye es de cero: nunca se hacen actualizaciones a una tabla ya existente. Una tabla de encaminamiento vieja no se desecha hasta que se han identificado los cambios entre las dos tablas. Brevemente, el cálculo consiste en los pasos indicados abajo. Ver el RFC 1583 para más detalles sobre la implementación del algoritmo.
- Las rutas intra-area se calculan construyendo el árbol mínimo para cada área conectada usando el mismo "router" como raíz del árbol. El "router" calcula además si el área puede actuar como área de tránsito para enlaces virtuales.
- Las rutas inter-area se calculan examinando los SLA. Para los ABR(que forman parte de la troncal) sólo se utilizan los anuncios correspondientes a la troncal(es decir, un ABR siempre encaminará tráfico inter-area a través de la troncal).
- Si el "router" está conectado a una o más áreas de tránsito, el "router" sustituye las rutas que haya calculado por rutas que pasen por áreas de tránsito si estas son mejores.
- Las rutas externas se calculan por examinando los anuncios externos del AS. Las localizaciones de los ASBR ya se conocen debido a que se determinan como cualquier otra ruta intra-area o inter-area.
Cuando el algoritmo produce rutas de igual coste, OSPF puede balancear uniformemente la carga a través de ellas. El número máximo de rutas iguales admitidas depende de la implementación.
Un "router" anuncia periódicamente el estado de su enlace, por lo que la ausencia de un anuncio reciente indica a los vecinos del "router" que no está activo. Todos los "routers" que hayan establecido comunicación bidireccional con un vecino ejecutan un contador de inactividad para detectar ese suceso. Si no se resetea el contador, al final se desbordará y el evento asociado sitúa el estado del vecino en "down". Esto significa que la comunicación se debe establecer desde cero, incluyendo la resincronización de las bases de datos. Un "router" también relanza sus anuncios cuando su estado cambia.
Un "router" puede lanzar diversos anuncios para cada área. Estos se propagan a través del área por el procedimiento de inundación. Cada "router" emite un RLA. Si el "router" es además el DR para una o más de las redes del área, originará NLAs para estas. Los ABR generan una SLA para cada destino inter-area conocido. Los ASBR originan un ASL para cada destino externo conocido. Los destinos se anuncian uno cada vez de tal forma que el cambio de una sola ruta puede inundar la red sin tener que enviar el resto de las rutas. Durante el proceso de inundación, un sólo LSU puede llevar muchos anuncios.
OSPF es un protocolo de encaminamiento complejo, como las anteriores secciones han hecho patente. Los beneficios de esta complejidad(sobre RIP) son los siguientes:
- Debido a las bases de datos de estados de enlaces sincronizadas, los "router" OSPF convergerán mucho más rápido que los "routers" RIP tras cambios de topología. Este efecto se hace más pronunciado al aumentar el tamaño del AS.
- Incluye encaminamiento TOS("Type of Service") diseñado para calcular rutas separadas para cada tipo de servicio. Para cada destino, pueden existir múltiples rutas, cada una para uno o más TOSs.
- Utiliza métricas ponderadas para distintas velocidades el enlace. Por ejemplo, un enlace T1 a.544 Mbps podría tener una métrica de 1 y un SLP a 9600 bps una de 10.
- Proporciona balanceamiento de la carga ya que una pasarela OSPF puede emplear varios caminos de igual coste mínimo.
- A cada ruta se le asocia una máscara de subred, permitiendo subnetting de longitud variable(ver Subredes) y supernetting (ver CIDR(Classless Inter-Domain Routing)).
- Todos los intercambios entre "routers" se pueden autentificar mediante el uso de passwords.
- OSPF soporta rutas específicas de hosts, redes y subredes.
- OSPF permite que las redes y los hosts contiguos se agrupen juntos en áreas dentro de un AS, simplificando la topología y reduciendo la cantidad de información de encaminamiento que se debe intercambiar. La topología de un área es desconocida para el resto de las áreas.
- Minimiza los broadcast permitiendo una topología de grafo más compleja en la que las redes multiacceso tienen un DR que es responsable de describir esa red a las demás redes del área.
- Permite el intercambio de información de encaminamiento externa, es decir, información de encaminamiento obtenida de otro AS.
- Permite configurar el encaminamiento dentro del AS según una topología virtual más que sólo las conexiones físicas. Las áreas se pueden unir usando enlaces virtuales que crucen otras áreas sin requerir encaminamiento complicado.
- Permite el uso de enlaces punto a punto sin direcciones IP, lo que puede ahorrar recursos escaso en el espacio de direcciones IP.
Una descripción detallada de IP se puede encontrar en los siguientes RFCs:
- RFC 1245 - Análisis del protocolo OSPF
- RFC 1246 - Experiencia con el protocolo OSPF
- RFC 1253 - OSPF Versión 2: MIB("Management Information Base")
- RFC 1370 - Condiciones de aplicabilidad de OSPF
- RFC 1583 - OSPF Versión 2
IS-IS es un protocolo similar a OSPF: también emplea el estado del enlace, el algoritmo SPF("Shortest Path First"; ver Estado del enlace, primero el camino más corto para más detalles). Sin embargo, IS-IS es un protocolo OSI usado para los paquetes CLNP("Connectionless Network Protocol") en un dominio de encaminamiento. CLNP es el protocolo OSI más comparable a IP.
El IS-IS integrado extiende IS-IS para compararse a TCP/IP. Se describe en el RFC 1195. Su meta es proporcionar un sólo(y eficiente) protocolo de encaminamiento para TCP/IP y para OSI. Su diseño hace uso del protocolo de encaminamiento OSI IS-IS, aumentado con información IP específica, y proporciona apoyo explícito para el subnetting IP, máscaras de red variables, encaminamiento TOS, y encaminamiento externo, además de recurso para la autentificación. El IS-IS integrado se basa en el mismo algoritmo de encaminamiento que OSPF.
No emplea encapsulación mutua de los paquetes IP y CLNP: ambos tipos se envían tal como son, ni cambia el comportamiento del "router" como ambas pilas de protocolos podrían esperar. Se comporta como un IGP en una red TCP/IP y en una red OSI. El único cambio es la adición de información adicional relacionada con IP.
IS-IS usa el término IS("Intermediate System") para referirse a un "router" IS-IS router, pero usaremos el termino "router", ya que se usa con libertad en el est IS-IS integrado.
IS-IS agrupa las redes en dominios de modo análogo a OSPF. Un dominio de encaminamiento es análogo a un AS, y se subdivide en áreas, exactamente como OSPF. Aquí hay una descripción de los aspectos más importantes del encaminamiento IS-IS. Cuando es posible, se hacen comparaciones con conceptos equivalentes de OSPF.
- Los "routers" se dividen en "routers" de nivel 1, que no saben nada de la topología fuera de sus áreas, y de nivel 2, que conocen la topología de nivel superior, pero no saben nada de la topología de dentro de las áreas, a menos que sean también "routers" de nivel 1.
- Un "router" de nivel 1 puede pertenecer a más de un área, pero a diferencia de OSPF esto no se hace con propósitos de encaminamiento sino para facilitar la gestión del dominio, y normalmente por poco tiempo. Un "router" de nivel 1 reconoce a otro como un vecino si están en la misma área.
- Un "router" de nivel 2 reconoce a todos los demás "routers" de nivel 2 como vecinos. Un "router" de nivel 2 puede ser también un "router" de nivel 1 en un área, pero no en más.
- Un "router" de nivel 1 en IS-IS no puede tener un enlace con un "router" externo(en OSPF un "router" interno puede ser una ASBR).
- Hay una troncal de nivel 2 que contiene todos los "routers" de nivel dos, pero a diferencia de OSPF, debe estar conectada físicamente.
- El esquema de dirección OSI identifica explícitamente el área objetivo de un paquete, permitiendo una selección sencilla de las rutas del modo siguiente:
- Los "routers" de nivel 2 encaminan hacia el área sin importarles su estructura interna.
- Los "routers" de nivel 1 encaminan hacia el destino si está en su área, o al "router" de nivel 2 más cercano no es así.
- Las redes multiacceso usan el concepto de DR("Designated Router"). Para evitar el problema "n(n-1)/2'' descrito en OSPF, IS-IS implementa un pseudonodo para la LAN. Se considera que cada "router" conectado a la LAN tiene un enlace con el pseudonodo, pero ninguno con los demás "routers" de la LAN. El DR actúa representando al pseudonodo.
IS-IS integrado permite una mezcla considerable de las dos pilas de protocolo, sujeto a ciertas restricciones sobre la topología. Se definen tres tipos de rutas:
- IP-only
- Un "router" que usa IS-IS como protocolo de encaminamiento y para IP y no soporta protocolos OSI(por ejemplo, tales "routers" no serían capaces de transmitir paquetes CLNP).
- OSI-only
- Un "router" que usa IS-IS como protocolo de encaminamiento para OSI pero no usa IP.
- Dual
- Un "router" que usa IS-IS como un único protocolo de encaminamiento integrado tanto para IP como para OSI.
Es posible tener un dominio mixto que contenga "routers" IS-IS, algunos de los cuales son "IP-only", algunos "OSI-only" y algunos del tipo "dual". Cada área dentro de un dominio se configura como OSI, IP o "dual". Las áreas que han de soportar tráfico mixto deben tener todos los "routers" de nivel 1 del tipo "dual". Similarmente, los "routers" de nivel 2 en un dominio mixto deben ser "dual" si el tráfico mixto se tiene que encaminar entre áreas.
Como sugiere su nombre, el IS-IS integrado ofrece una solución de encaminamiento para redes multi-protocolo. OSPF, como otros protocolos de encaminamiento TCP/IP, utiliza una estrategia llamada SIN("Ships In the Night") para manejar cuestiones de coexistencia. En la estrategia SIN, cada "router" multi-protocolo ejecuta un proceso separado para cada capa de red(IP y OSI). Un "router" SIN permite que los gestores de la red inserten nuevos protocolos de encaminamiento basados en SIN, como OSPFS, uno a uno, pero los protocolos existen con independencia unos de otros.
La mayoría de los distribuidores de estos protocolos ha elegido seguir con SIN, debido a la pujanza de TCP/IP. Unos cuantos han anunciado que en el futuro apoyarán el IS-IS integrado.
Tabla de contenidos  Protocolos de encaminamiento exterior
Protocolos de encaminamiento exterior